In questo articolo vediamo lo schema completo per i test di ipotesi che riguardano il confronto tra medie.

INDICE
CONFRONTO TRA MEDIE
Il confronto tra medie è una procedura che serve a verificare l’uguaglianza della media di un campione rispetto alla media di un altro campione o della popolazione
SCHEMA LOGICO:
Per chi si è appena approcciato al mondo della statistica l’analisi della teoria delle medie ha una teoria molto complessa.
Quindi vi consiglio di tenere a portata di mano una bella camomilla onde evitare di cadere nello stato di disperazione se non avete ben capito dopo una sola lettura questo articolo.
Armatevi di pazienza e cercate di affrontare questo argomento a sangue freddo e con i piedi di piombo.
Per prima cosa cominciamo a distinguere quattro casistiche principali:
- Campione VS popolazione
- 2 campioni indipendenti
- 2 campioni dipendenti (appaiati)
- K campioni indipendenti
È molto importante capire bene da quale di questi quattro casi voi state partendopoiché in base a ognuno di questi affronterete la questione con strumenti diversi.
CAMPIONE VS POPOLAZIONE
Questo è il primo e più elementare caso che viene trattato nell’ambito inferenziale quando si comincia a parlare del test sulla media.
In parole molto semplici vogliamo capire se la media di un certo gruppo è uguale alla media della popolazione.
In questo caso partiamo dalla conoscenza certa della media di una certa popolazione pari a µ e vogliamo testare se un certo suo gruppo presenta una media analoga.
Per fare questo test andiamo a selezionare un campione che rappresenti in modo appropriato questo gruppo e ne rileviamo la numerosità n, il valore medio ed eventualmente la deviazione standard campionaria.

Arrivati a questo punto quando dovremo procedere all’impostazione del test si aprirà un bivio.
Dovremo infatti capire se la varianza della popolazione è nota oppure non è nota.
VARIANZA POP NOTA
Con la varianza nota risolveremo il test utilizzando la classica distribuzione normale standardizzata.
L’errore standard (SE) e la statistica-test saranno rispettivamente:
$$ SE = \frac{\sigma}{\sqrt{n}} $$
$$ \text{z-test} = \frac{\bar x – \mu}{SE} $$
VARIANZA POP IGNOTA
Mentre quando non è nota la varianza utilizziamo una distribuzione t-student con n-1 gradi di libertà.
Questa distribuzione infatti è più volatile rispetto alla normale z.
In questo caso l’errore standard (SE) e la statistica-test sono:
$$ SE = \frac{s}{\sqrt{n}} $$
$$ \text{z-test} = \frac{\bar x – \mu}{SE} \text{ con } n-1 \text{ g.d.l} $$
Riporto qui sotto uno schema grafico che rappresenta questa tipologia:

Se ti interessa affrontare questo caso ti consiglio andare al seguente link per capire come impostare il test sulla media del campione con la popolazione.
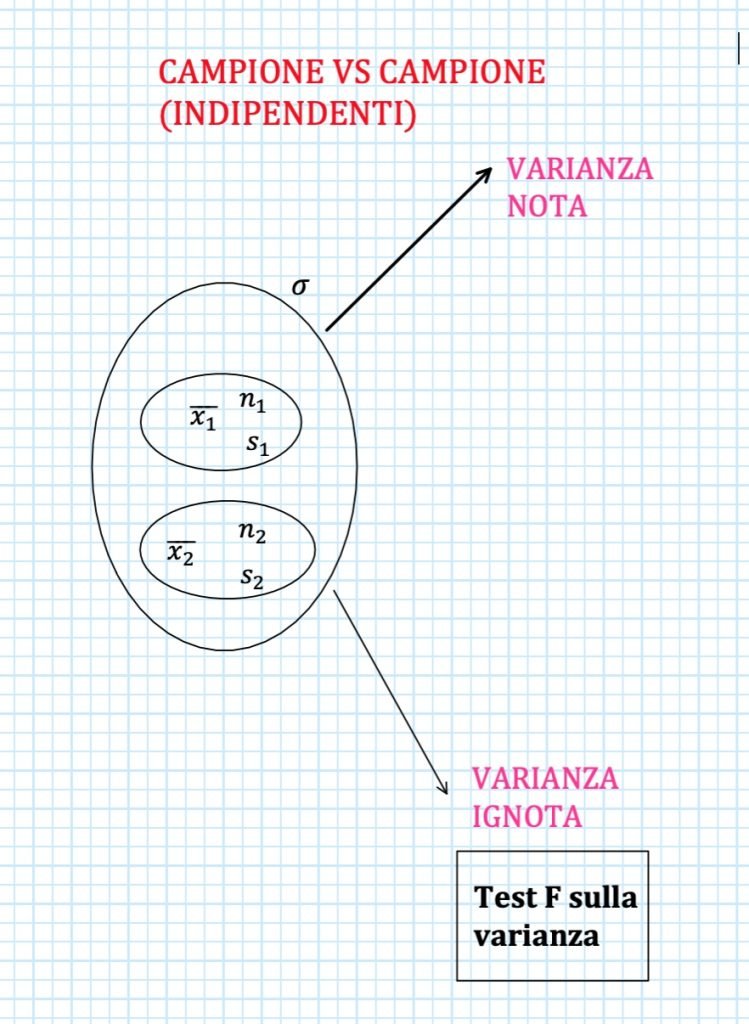
CONFRONTO TRA MEDIE PER DUE CAMPIONI INDIPENDENTI
Il secondo caso generale è quello in ci troviamo di fronte a due campioni indipendenti.
In particolare vogliamo scoprire se la media di due gruppi di una stessa popolazione (o di due popolazioni) può essere considerata la stessa oppure no.
Quindi andiamo a selezionare all’interno della popolazione due campioni indipendentiche rappresentino al meglio i due gruppi.
Fatto ciò andiamo a rilevare su questi campioni le numerosità, le medie e le deviazioni standard.

Una volta che siamo sicuri di essere approdati in questo caso dobbiamo preoccuparci di comprendere se le varianze delle popolazioni di riferimento siano meno note.
Nel primo caso possiamo immediatamente stabilire se le due varianze di riferimento sono uguali oppure no (perché le conosciamo).
Mentre nel secondo caso dovremo ricorrere al test F sulla varianza per stabilirlo.
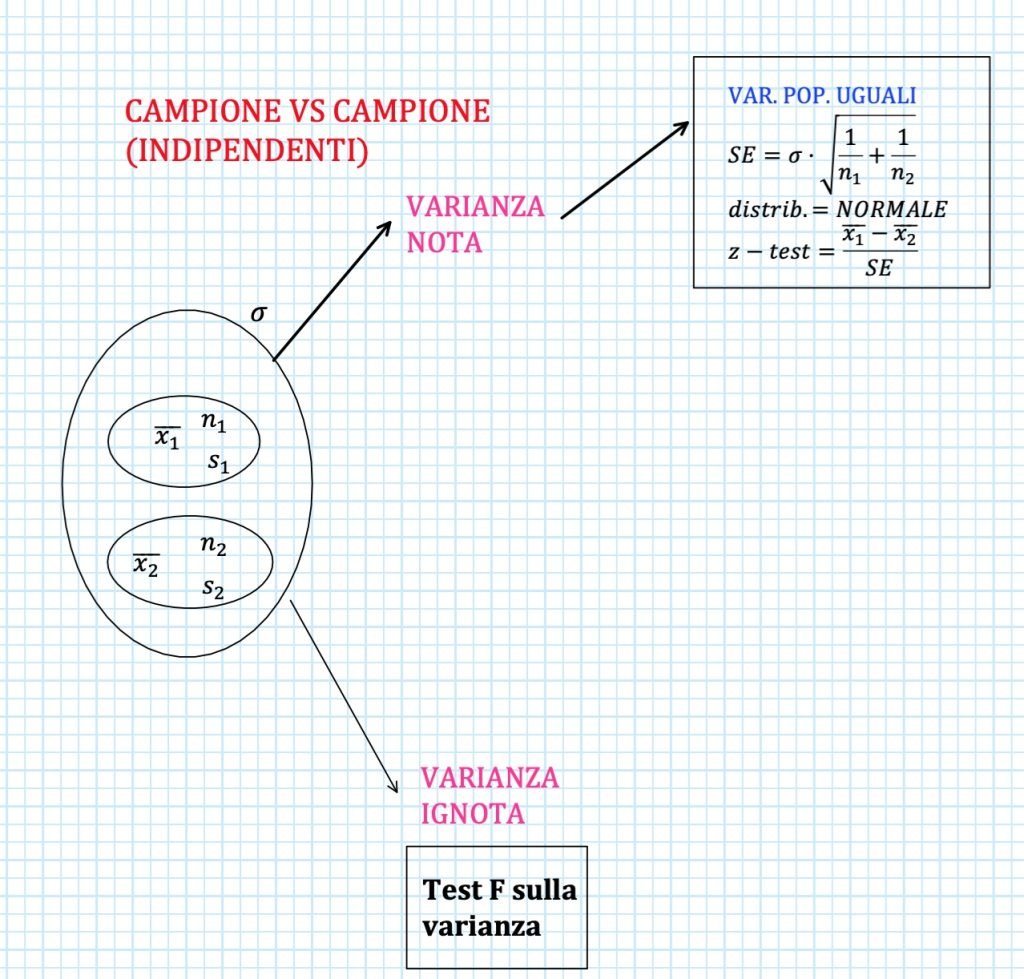
VARIANZA DELLA POPOLAZIONE NOTA
Il primo caso da cui partiamo per il confronto tra medie di campioni indipendenti è quello delle varianze note, che distinguiamo in uguali oppure diverse.
VARIANZE UGUALI – VAR POP NOTA
Nel caso in cui le varianze possono essere considerate uguali significa che anche la popolazione di riferimento per questi due gruppi ha quella varianza.
Allora bisognerà capire se questa varianza della popolazione è nota oppure ignota.
Se la varianza della popolazione è nota risolviamo il test utilizzando una distribuzione normale standardizzata.
L’errore standard (SE) e la statistica test sono rispettivamente:
$$ SE = \sigma \cdot \sqrt{\frac{1}{n_1} +\frac{1}{n_2} } $$
$$ \text{z-test} = \frac{\bar x_1 – \bar x_2}{SE} $$
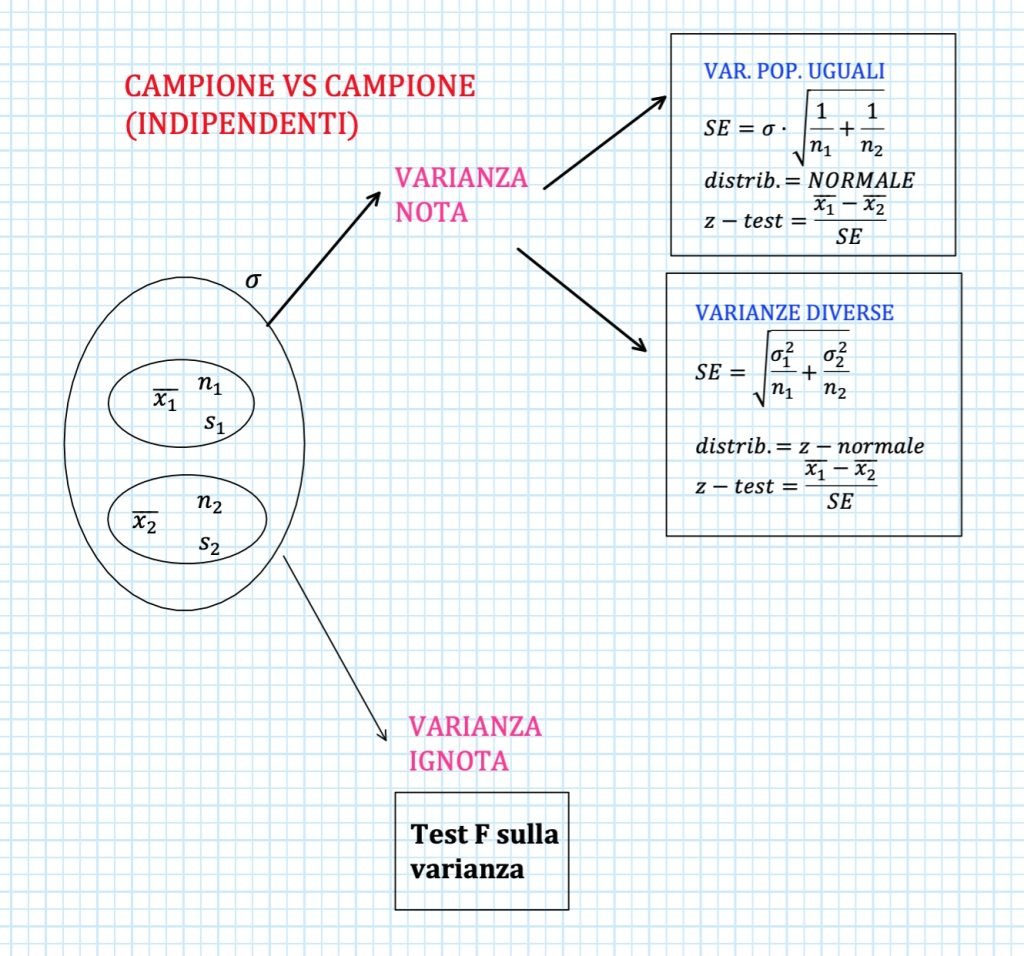
VARIANZE DIVERSE – VAR POP NOTA
Quando le varianze delle popolazioni cui i due campioni appartengono sono note e diverse tra di loro usiamo sempre una distribuzione norma con standard error (SE) pari a:
$$ SE = \sqrt{\frac{\sigma_1^2}{n_1} + \frac{\sigma_2^2}{n_2}} $$
Mentre il valore dello z-test che usiamo per calcolare il p-value è sempre:
$$ \text{z-test} = \frac{\bar x_1 – \bar x_2}{SE} $$
SCOPRI L’INFERENZA STATISTICA
Impara tutti i segreti per svolgere correttamente i test di ipotesi sulle medie, le proporzioni e le varianze.
Un fantastico percorso ti attende con i corsi di statistica: dalle basi fino ai livelli avanzati.
VARIANZA DELLE POPOLAZIONI IGNOTE
Il secondo caso che riguarda il test sulla media per due campioni indipendenti (quello più tipico) si verifica quando non conosciamo la varianza delle popolazioni di riferimento per i due campioni.
In questo caso il nostro primo sforzo è quindi rivolto a comprendere se possiamo considerare o meno uguali le due varianze.
A tale scopo esiste un test apposito che è il test F sulla varianza.
L’esito di questo test ci indica se possiamo considerare (entro certi limiti) uguali o diverse le varianze per le due popolazioni di riferimento
VARIANZE UGUALI – VAR POP IGNOTA
Se l’esito del test F sulla varianza è positivo, nel senso che “vince” l’ipotesi nulla, allora possiamo considerare che le popolazioni di riferimento per i due campioni abbiamo la stessa varianza.
Possiamo dunque calcolare una sorta di “varianza media” campionarie nel seguente modo:
$$ \bar s^2 = \frac{s_1^2 \cdot (n_1-1) +s_2^2 \cdot (n_2-1) }{n_1 + n_2 -2} = \frac{\text{DEV}_1 +\text{DEV}_2 }{n_1 + n_2 -2} $$
La deviazione standard media risulta ovviamente dalla radice quadrata della varianza media.
$$ \bar s = \sqrt{\frac{s_1^2 \cdot (n_1-1) +s_2^2 \cdot (n_2-1) }{n_1 + n_2 -2}} = \sqrt{\frac{\text{DEV}_1 +\text{DEV}_2 }{n_1 + n_2 -2}} $$
In generale vale sempre che quando la varianza della popolazione non è nota allora utilizziamo una distribuzione t-student.
I gradi di libertà che utilizziamo nel caso di varianza uguale sono n1 + n2 -2
$$ \text{g.d.l} = n_1+n_2 -2 $$
Questa quantità è data dalla somma dei gradi di libertà dei due campioni
$$ \text{g.d.l} = (n_1-1)+(n_2 -1) $$
L’errore standard risulta essere:
$$ SE = \bar s \cdot \sqrt{\frac{1}{n_1} + \frac{1}{n_2}} $$
Mentre la statistica-test
$$ \text{t-test} = \frac{\bar x_1 – \bar x_2}{SE} \quad \text{con } n_1 +n_2 -2 \text{ g.d.l.} $$
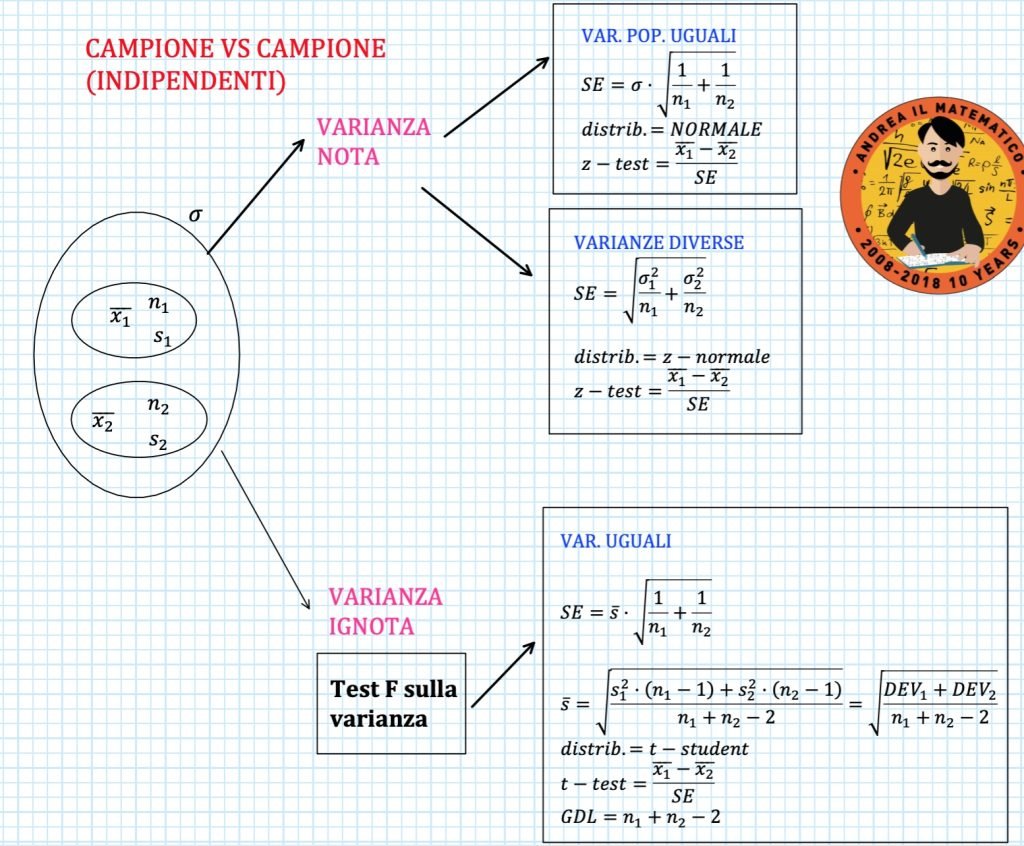
VARIANZE DIVERSE
Quando le varianze sono considerate diverse allora non avremo bisogno della varianza media.
L’errore standard risulterà pari a:
$$ SE = \sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}} $$
I gradi di libertà vengono calcolati con questa formula abbastanza complessa:
La statistica test è sempre:
$$ \text{t-test} = \frac{\bar x_1 – \bar x_2}{SE} $$
In questo caso il calcolo dei gradi di liberà risulta dalla seguente formula
$$ g.d.l = \frac{\left( \frac{s^2_1}{n_1} + \frac{s^2_2}{n_2} \right)^2}{ \frac{ \left( \frac{s^2_1}{n_1 } \right)^2}{n_1 – 1} + \frac{ \left( \frac{s^2_2}{n_2 } \right)^2}{n_2 – 1} }$$
Guardate la figura sotto, rileggete il testo e poi passate ad analizzare un caso alla volta con il link sotto la figura.
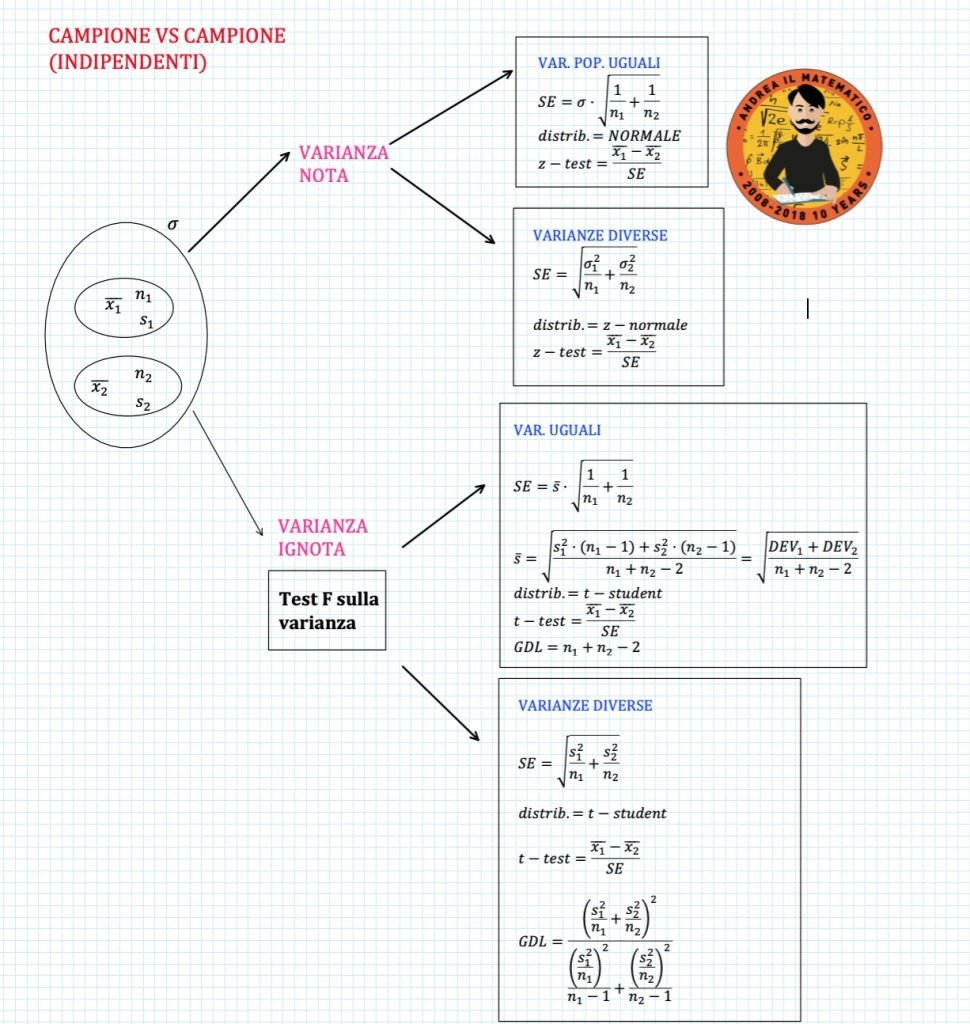
Accedi al link per vedere come si imposta il test di ipotesi nel caso di due campioni indipendenti.
DUE CAMPIONI DIPENDENTI (APPAIATI)
Il terzo caso in cui possiamo capitare quando facciamo un confronto tra medie è quello dei campioni dipendenti.
Il caso tipico che viene analizzato è quello relativo ai campioni appaiati.
Questo caso di verifica in genere quando vogliamo misurare l’evoluzione di una certa situazione.
Immaginate ad esempio che uno stesso gruppo di studenti ripeta un test di matematica per due volte.
Vogliamo ad esempio capire se c’è stato un cambiamento nei due risultati (in meglio o in peggio).
Contrapporremo due ipotesi.
L’ipotesi nulla H0 che sostiene che tra i due risultati non risulta esserci un cambiamento e l’ipotesi alternativa H1 che sostiene l’evidenza di un cambiamento.
Nell’ipotesi nulla sosteniamo che la differenza delle medie è pari a zero, mentre in quella alternativa sosteniamo che la media è diversa da zero.
Diversamente dai seguenti approcci in questo caso la numerosità del campione n deve per forza rimanere inalterata.
In questo caso costruiamo una nuova variabile d pari alla differenza tra il valore finale e quello iniziale.
$$ d = \text{differenze }= x_1 – x_2 $$
Di questa nuova variabile andiamo a calcolarci il valore medio e la varianza campionaria.
$$ \bar d = \text{ media delle differenze} = \bar x_2 – \bar x_1 $$
$$ \sigma _d = \text{ dev. st. delle differenze} $$

Ora dobbiamo tenere bene in mente il solito bivio di ragionamento in cui incorriamo, derivante dalla domanda:
La varianza della popolazione delle differenze è nota?
VARIANZA POP. NOTA
Se la varianza delle differenze è nota usiamo la solita normale standardizzata z.
L’errore standard (SE) e la statistica test saranno in questo caso:
$$ SE = $$ \frac{\sigma_d}{\sqrt{n}} $$
$$ \text{z-test} = \frac{\bar x_1 – \bar x_2}{SE} = \frac{\bar d}{SE} $$
VARIANZA POP. IGNOTA
Quando invece la varianza delle differenze non è nota usiamo la t-student con n-1 g.d.l. e avremo che:
$$ SE = \frac{s_d}{\sqrt{n}} $$
$$ \text{t-test} = \frac{\bar x_1 – \bar x_2}{SE} = \frac{\bar d}{SE} $$
$$ \text{g.d.l. } = n-1 $$

Accedi al link per vedere un esempio con campioni dipendenti (appaiati)
K CAMPIONI INDIPENDENTI
Il quarto e ultimo caso relativo al confronto tra medie è quello in cui verifichiamo se le medie relative a k gruppi indipendenti di una popolazione possono essere considerate uguali.
In questo caso dobbiamo servirci di uno strumento più potente rispetto alla t-student.
In particolare usiamo il metodo ANOVA.
HAI QUALCHE DOMANDA?
Se questo articolo ti ha ispirato qualche dubbio scrivi pure la tua domanda nei commenti.
Le tue domande sono molto importanti per tutti gli utenti che hanno i tuoi stessi dubbi.
IMPARA LA STATISTICA
Comincia un fantastico viaggio alla scoperta di questa affascinante materia partendo da zero.
Si comincia dalla statistica descrittiva, passando per le probabilità si arriva all’inferenza.
Comincia subito il tuo percorso e migliora le tue abilità.
L’ARTICOLO TI è PIACIUTO ?
Se questo contenuto ti è piaciuto e vorresti che anche altri utenti possano goderne di questo ed altri ancora sostieni il progetto offrendomi un semplice caffè virtuale
Questo semplice gesto per me significa moltissimo e può essere un forte impulso per lo sviluppo di tutto il progetto di divulgazione matematica
Una risposta
Buongiorno, ho difficoltà a capire il concetto di clustering nei tipi di campionamento… potrebbe per favore spiegarmelo e farmi un esempio? Grazie davvero!!!!
angela