Oggi vediamo la procedura per confrontare due medie campionarie.
Il test sul confronto tra due medie campionarie viene effettuato per verificare se le medie di due campioni indipendenti possono essere considerate uguali
ESEMPIO
Vogliamo testare se in due pizzerie diverse la quantità di mozzarella (misurata in grammi) è la stessa.
Nella prima pizzeria testiamo un campione di 15 pizze, mentre nella seconda un campione di 20 pizze.
I riportiamo i seguenti dati campionari:
PIZZERIA 1
$$ n_1 = 15 \quad \bar x_1 = 123 \quad s_1= 18 $$
PIZZERIA 2
$$ n_2 = 20 \quad \bar x_2 = 115 \quad s_2= 10 $$
Si verifichi l’ipotesi al livello del 10% che la quantità media sia uguale per entrambe le pizzerie sotto le seguenti ipotesi:
- È nota la deviazione standard della popolazione pari a 14
- Non è nota la varianza della popolazione ma consideriamo uguali le varianze dei campioni
- Consideriamo diverse le varianze dei campioni.
VARIANZA DELLA POPOLAZIONE NOTA
Partiamo dal caso in cui la varianza della popolazione è nota.
Cominciamo ad impostare il test di ipotesi.
L’ipotesi nulla H0 afferma che le medie dei campioni sono uguali e quindi la differenza delle medie delle popolazioni di riferimento è pari a zero.
$$ H_0: \mu_1 -\mu_2 =0$$
Da notare che per le medie delle popolazioni utilizziamo la lettera greca mu (𝜇) in contrapposizione alle medie campionarie dove utilizziamo la lettera romana x barrata.
Mentre l’ipotesi alternativa H1 afferma il contrario, ovvero che le medie sono diverse, e quindi la differenza è diversa da zero
$$H_0: \mu_1 -\mu_2 =0 $$
Siccome la varianza della popolazione è nota useremo la normale standardizzata.
Come valore della deviazione standard usiamo 20.
Ora passiamo alle caratteristiche della distribuzione normale.
La media è pari alla differenza delle medie ipotizzate dall’ipotesi nulla ovvero zero:
$$ \text{media normale} = 0
L’errore standard (SE) è calcolato come:
$$ SE = \sigma \cdot \sqrt{\frac{1}{n_1} + \frac{1}{n_2}} $$
Ovvero inserendo i numeri:
$$ SE = 14 \cdot \sqrt{\frac{1}{15} + \frac{1}{20}} = 4,782$$
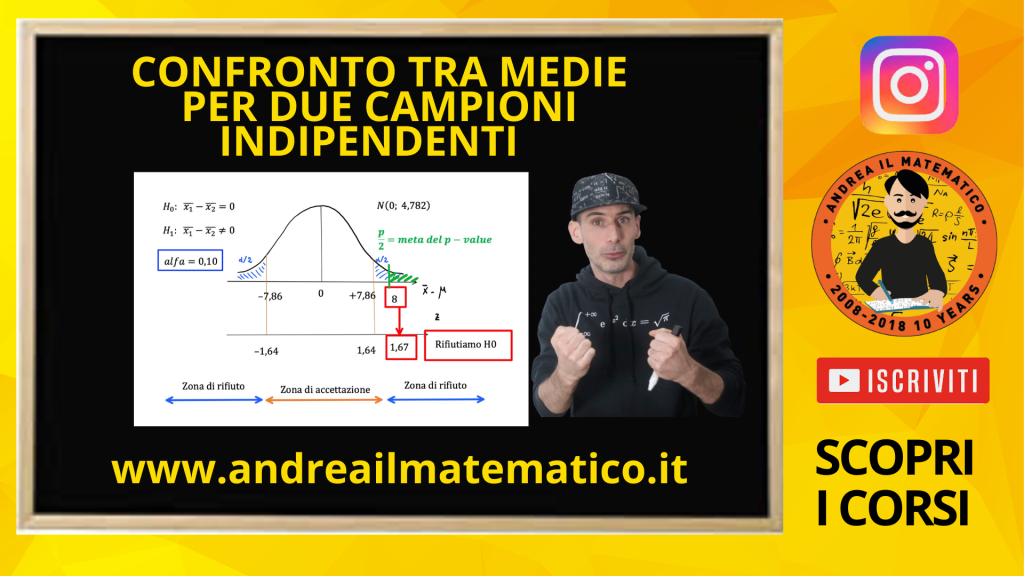
RAPPRESENTAZIONE GRAFICA E VALORE DI Z
Andiamo ora a visualizzare graficamente la situazione.
Rappresentiamo la campana gaussiana con media pari a zero e deviazione standard 4,782.
Sotto la gaussiana rappresentiamo due linee orizzontali.
Sulla prima è rappresentata la differenza tra le medie campionarie.
Mentre sulla seconda i valori standardizzati z.
Sappiamo ora che vogliamo testare questa differenza con un livello di confidenza alfa pari al 10% cioè 0,10.
Sapendo che il test è a due code dobbiamo “smezzare” questo livello di alfa in due parti eguali, metà sulla destra e metà sulla sinistra,
Pertanto ci interessa il valore di z in corrispondenza del quale l’area a destra compresa tra la campana e l’asse orizzontale è pari a 0,05.
Analogamente possiamo dire che l’area a sinistra è pari a:
$$ \text{AREA SX} = 1 – \frac{\alpha}{2} = 1- \frac{0,10}{2} = 1-0,05= 0,95 $$
Il valore di z che dobbiamo ricercare è il 95-esimo percentile di z, ovvero:
$$ z_{0,95} = ??? $$
Per trovare questo valore possiamo andare sulle tavole della normale standardizzata con aree a sinistra.
Ricerchiamo il valore più vicino a 0,95 e troviamo il numero 1,96.
$$ z_{0,95} = 1,645 $$
Con Excel la formula da usare è:
$$ = \text{INV.NORM.S (0,95)} $$

A questo punto dobbiamo tenere presente che l’altro valore di z è quello opposto, ovvero –1,64

CALCOLO DEGLI ESTREMI E ZONA DI ACCETTAZIONE
Adesso è nostro compito calcolare i valori degli estremi entro i quali risulta verificata l’ipotesi nulla.
Per calcolarci questi valori usiamo la formula:
$$ x_{1,2} = 0 \pm z_{0,95} \cdot SE $$
Nel nostro caso:
$$ x_{1,2} = 0 \pm 1,645 \cdot 4,782 = 7,87 $$
Questo significa che se la differenza tra la media del campione e la media della popolazione è compresa tra questi due estremi accettiamo l’ipotesi nulla.
$$ \text{se } \bar x_1 – \bar x_2 \in (-7,86 , +7,86) \to \text{ accetto } H_0 $$
Altrimenti rifiutiamo l’ipotesi nulla e accettiamo l’ipotesi alternativa H1.

ESITO DEL TEST
Calcoliamo ora la differenza tra le medie campionarie
$$ \bar x_1 – \bar x_2 = 123-115 = 8 \not\in (-7,86 , +7,86) \to \text{ rifiuto } H_0 $$
Siccome 8 non appartiene alla zona di accettazione di H0 Rifiutiamo l’ipotesi nulla al livello di significatività del 5%.
Ovvero riconosciamo il fatto che le medie dei due campioni sono diverse.

STATISTICA-TEST E P-VALUE
Quando si chiude il test di ipotesi sarebbe sempre bene calcolare il p-value.
Il p-value indica la probabilità che l’ipotesi nulla sia errata rispetto al dato campionario.
Possiamo considerarlo come il massimo valore di alfa ammissibile affinché la nostra ipotesi nulla possa considerarsi falsa.
Geometricamente parlando intendiamo l’area estrema sottesa tra la funzione considerata e l’asse delle x in corrispondenza del dato campionario.
Ovviamente se il test è bilaterale dobbiamo raddoppiare questo valore.
Mentre se il test è monolaterale destro o sinistro lo calcoliamo a destra o a sinistra.
Per poter calcolare il p-value serve calcolare la statistica-test.
Questa non è altro che il nostro dato campionario (differenza) standardizzato.
Per calcolare la statistica-test usiamo la seguente formula:
$$ \text{z-test} = \frac{\bar x_1 – \bar x_2}{SE} = \frac{\bar x_1 – \bar x_2}{\sigma \cdot \sqrt{\frac{1}{n_1} + \frac{1}{n_2}} } $$
Inseriamo i dati a nostra disposizione:
$$ \text{z-test} = \frac{8}{4,782} = 1,67 $$
Il p-value è il doppio dell’area verde che si trova a destra di questo valore sotto la normale standardizzata (vedi figura sotto).

Come si capisce dal grafico il p-value (doppio area verde) deve essere inferiore ad alfa (area blu)
Per calcolarlo faremo:
$$ \text{p-value} = 2 \cdot \left ( 1 – \oint_{NS} (1,67) \right) $$
Dove l’integrale cerchiato è tutta l’area che si trova a sinistra della statistica-test (z=1,67) tra la normale standardizzata (NS) e l’asse z.
Potremo anche scrivere:
$$ \text{p-value} = 2 \cdot \left ( 1 – F_{NS} (1,67) \right) $$
oppure ancora
$$ \text{p-value} = 2 \cdot \left( 1 – \int_{- \infty}^{1,67} f(z) d z \right) $$
dove la funzione f(z) è la normale standardizzata.
Per trovare questo valore andiamo sulle tavole della z in corrispondenza del valore 1,67
Oppure usando Excel possiamo applicare la formula:
$$ = \text{DISTRIB.NORM.ST (1,67)} $$
Come valore otteniamo 0,9528
Il nostro p-value sarà dunque:
$$ \text{p-value} = 2 \cdot \left ( 1 – 0,9528 \right) = 0,0943$$
Come predetto più piccolo, anche se molto vicino, al valore di alfa del 10%.
SCOPRI L’INFERENZA STATISTICA
Impara tutti i segreti per svolgere correttamente i test di ipotesi sulle medie, le proporzioni e le varianze.
Un fantastico percorso ti attende con i corsi di statistica: dalle basi fino ai livelli avanzati.
VARIANZA DELLA POPOLAZIONE IGNOTA
Se la varianza è ignota allora la distribuzione di riferimento diventa la t-student.
A questo punto bisogna comprendere se consideriamo la varianza dei due gruppi può essere considerata la stessa oppure no.
Per fare questa operazione esiste un test apposito, chiamato il test F sulla varianza di Fisher-Snedecor.
L’esito del test dipende dal livello di significativa che prendiamo in considerazione che solitamente è il 5%.
In questo caso non ci interessa verificarlo e quindi passiamo ad analizzare come ci comportiamo nei due casi.
VARIANZA DEI CAMPIONI IGNOTA E UGUALE
Se consideriamo uguale la varianza dei due campioni abbiamo bisogno di un valore da attribuire a questa varianza, dal momento che non conosciamo la vera varianza della popolazione.
VARIANZA MEDIA, T-STUDENT ASSOCIATO AD ALFA
Utilizziamo perciò la varianza media tra i due campioni.
Per calcolarlo facciamo una media delle varianze campionarie ponderata per i gradi di libertà (g.d.l = n_1 + n_2 -2) .
In alternativa possiamo anche fare la somma delle devianze divisa per i g.d.l.
La radice quadrata di questa varianza ci da la deviazione standard la cui formula è:
$$ \bar s = \sqrt{\frac{s^2_1 \cdot (n_1 -1) + s^2_2 \cdot (n_2 -1) }{n_1 + n_2 -2}} = \sqrt{\frac{\text{DEV}_1 + \text{DEV}_2 }{n_1 + n_2 -2}} $$
Riportiamo i dati relativi ai campioni:
PIZZERIA 1
$$ n_1 = 15 \quad \bar x_1 = 123 \quad s_1= 18 $$
PIZZERIA 2
$$ n_2 = 20 \quad \bar x_2 = 115 \quad s_2= 10 $$
Inseriamoli nella formula della varianza media:
$$ \bar s = \sqrt{\frac{18^2 \cdot (15-1) + 10^2 \cdot (10-1)}{15+20-2}} = 13,39 $$
Ora troviamo l’errore standard associato al test di ipotesi che segue sempre la formula vista per il caso della varianza nota:
$$ SE = \sigma \cdot \sqrt{\frac{1}{n_1} + \frac{1}{n_2}} $$
$$ SE = 13,39 \cdot \sqrt{ \frac{1}{15} + \frac{1}{20}} = 4,57 $$
Analogamente a come abbiamo fatto nel caso della normale calcoliamo il percentile 0,95 della t-student con n1+n2-2 g.d.l.
$$ g.d.l = n_1 + n_2 -2 = 15 +20-2 = 33 $$
Cerchiamo il valore di t nella tavola leggendo sulla riga relativa ai 33 g.d.l. e se l’area è a destra sulla colonna relativa a 0,05.
Se non troviamo il 33 andiamo sul più vicino ad esempio 30 oppure facciamo un’interpolazione tra il valore che leggiamo sul 30 e quello che leggiamo sul 40.

Se guardiamo questa tavola il t-student che stiamo cercando risulta compreso tra i valori:
$$ 1,697< t_{0,95; \ 33} < 1,684 $$
Essendo più vicini i g.d.l. al 30 potremmo decidere di approssimarlo con il valore più basso.
Oppure se vogliamo aumentare leggermente la volatilità possiamo lasciare il più alto.
Potremmo fare una media semplice.
La strategia forse più corretta è l’interpolazione, facendo pesare al 70% il più basso e al 30% il più alto.
$$ t_{0,95; \ 33} \approx 1,697 \cdot 0,70 + 1,684 \cdot 0,30 = 1,693 $$
Se volessimo calcolarlo con Excel usiamo la funzione:
$$ \text{INVT (0,95 ; 0,33)} $$
Che ci restituisce il valore preciso pari a 1,692.
Usiamo pure 1,69 per svolgere i conti a mano e se i risultati che vi scrivono non vi tornano con un’approssimazione pari a 0,01 non vi preoccupate perché ho svolto i calcoli con Excel.
Grazie al valore di t-student siamo in grado di calcolare gli estremi entro i quali l’ipotesi nella è accettata.
IPOTESI, ESTREMI, RISULTATO E P-VALUE.
Le ipotesi del nostro test di ipotesi sono dunque:
$$ H_0 : \ \ \mu _1 – \mu_2 = 0 \quad H_1:\ \ \mu _1 – \mu_2 \ne 0 $$
Gli estremi entro cui accettiamo l’ipotesi nulla sono:
$$ x_{1,2} = 0 \pm t_{0,95; 33} \cdot SE = \pm 1,693 \cdot 4,57 = \pm 7,74 $$
Ora se il valore della media campionaria è interno all’intervallo delimitato dagli estremi accetteremo l’ipotesi nulla.
In caso contrario la rifiuteremo.
La differenza tra i valori medi risulta:
$$ \bar x_1 – \bar x_2 = 123-115 = 8 \not\in (-7,74 , +7,74) \to \text{ rifiuto } H_0 $$
Siccome 8 risulta al di fuori dell’intervallo rifiutiamo H0.

STATISTICA-TEST E P-VALUE
La statistica test associata al test di ipotesi risulta pari a:
$$ \text{t-test} = \frac{\bar x_1 – \bar x_2}{SE} = \frac{8}{4,57} = 1,75 $$
Il valore del p-value risulta inferiore certamente al valore di alfa.
Se vogliamo cercarlo sulle tavole della t-student andiamo nelle righe con 30 e 40 g.d.l. e cerchiamo il valore che più si avvicina a 1,75.

Come potete osservare dalla tavola il valore risulta compreso tra 1,679 (il più piccolo) e 2,021.
Quindi la metà del p-value (area a destra) è compreso tra 0,05 e 0,10.
Per avere un’idea più precisa possiamo fare il seguente ragionamento.
Prima interpoliamo il valori della t minima (in corrispondenza dell’area 0,10) e quelli della t massima (in corrispondenza dell’area 0,05) con il modo visto prima.
$$ \text{t}_{min} = 1,697 \cdot 0,70 + 1,684 \cdot 0,30 \approx 1,69 $$
$$ \text{t}_{max} = 2,042 \cdot 0,70 + 2,021 \cdot 0,30 \approx 2,04$$
Ora cerchiamo di capire quanta quota percentuale x c’è nella statistica test di questi due valori impostando la seguente equazione:
$$ 1,69 \cdot x + 2,04 \cdot (1-x) = 1,75 $$
Risolvendo abbiamo:
$$ x = \frac{2,04-1,75}{2,04-1,69} = 0,83 $$
Quindi attribuiamo questa percentuale al 5% e all’altra al 2,5%.
$$ \frac{\text{p-value}}{2} = 0,05 \cdot 0,83 + 0,025 \cdot (1- 0,083) = 0,04575 $$
Raddoppiando questo valore otteniamo circa 0,0915 che potrebbe essere l’approssimazionelineare del p-value.
Per andare sul sicuro possiamo comunque usare Excel impostando la funzione:
$$ = \text{DISTRIB.T.2T (1,75 ; 33) } $$
Il valore preciso del p-value è 0,0896.
Quindi non ci siamo sbagliati di molto.
VARIANZA DEI CAMPIONI IGNOTA E DIVERSA
Il terzo e ultimo caso che andiamo a trattare in questo articolo è quello in cui la varianza della popolazione non è nota e consideriamo diverse le varianze dei campioni.
La procedura seguita nell’ultimo caso è pressoché identica.
L’unica cosa che cambia è la determinazione dell’errore standard (SE) e il numero di gradi di libertà del test da cui ovviamente potrebbero dipendere le conclusioni.
Riportiamo ancora i dati per comodità:
PIZZERIA 1
$$ n_1 = 15 \quad \bar x_1 = 123 \quad s_1= 18 $$
PIZZERIA 2
$$ n_2 = 20 \quad \bar x_2 = 115 \quad s_2= 10 $$
Partiamo dall’errore standard (SE) che si calcola come:
$$ SE = \sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}} = \sqrt{\frac{18^2}{15} + \frac{10^2}{20}} = 5,157 $$
Attenzione anche se sembra identico a quello precedente in realtà non lo è.
Ho scelto per pigrizia di arrotondare tutti i dati alla seconda cifra decimale.
Ora viene la spinosa questione dei gradi di libertà.
La formula da utilizzare è abbastanza complessa ed è la seguente:
$$ \text{g.d.l} = \frac{\left( \frac{s^2_1}{n_1} + \frac{s^2_2}{n_2} \right)^2}{ \frac{ \left( \frac{s^2_1}{n_1 } \right)^2}{n_1 – 1} + \frac{ \left( \frac{s^2_2}{n_2 } \right)^2}{n_2 – 1} }$$
Inseriamo i dati in nostro possesso:
$$ g.d.l = \frac{\left( \frac{18^2}{15} + \frac{10^2}{20} \right)^2}{ \frac{ \left( \frac{18^2}{15 } \right)^2}{15 – 1} +\frac{ \left( \frac{10^2}{20 } \right)^2}{20 – 1} } = 20,42$$
Approssimando per difetto otteniamo 20 gradi di libertà.
Ancora per comodità riporto i risultati calcolarti con Excel:
$$ t_{0,95; \ 20} = 1,725 $$
Gli estremi escono:
$$ x_{1,2} = 0 \pm t_{0,95; \ 20} \cdot SE = \pm 1,725 \cdot 5,157 = 8,88$$
Poiché il valore della differenza tra le medie campionarie:risulta interna all’intervallo accettiamo l’ipotesi nulla.
$$ \bar x_2 – \bar x_1 = 8 \in (x_1, x_2) = ( -8,88, 8,88) \to \text {accettiamo } H_0 $$
La statistica test risulta essere:
$$ \text{t-test} = \frac{\bar x_2 – \bar x_1}{SE} = \frac{\bar x_2 – \bar x_1}{\sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}} = \frac{8}{5,157} = 1,551$$
Il valore del p-value calcolato con la formula di EXCEL
$$ = \text{DISTRIB.T.2T (1,551, 21} $$
risulta pari a 0,1358.
Ovviamente quest’ultimo maggiore del valore di alfa 10% avendo accettato l’ipotesi nulla.

HAI QUALCHE DOMANDA?
Se questo articolo ti ha ispirato qualche dubbio scrivi pure la tua domanda nei commenti.
Le tue domande sono molto importanti per tutti gli utenti che hanno i tuoi stessi dubbi.
IMPARA LA STATISTICA
Comincia un fantastico viaggio alla scoperta di questa affascinante materia partendo da zero.
Si comincia dalla statistica descrittiva, passando per le probabilità si arriva all’inferenza.
Comincia subito il tuo percorso e migliora le tue abilità.
L’ARTICOLO TI è PIACIUTO ?
Se questo contenuto ti è piaciuto e vorresti che anche altri utenti possano goderne di questo ed altri ancora sostieni il progetto offrendomi un semplice caffè virtuale
Questo semplice gesto per me significa moltissimo e può essere un forte impulso per lo sviluppo di tutto il progetto di divulgazione matematica
8 risposte
Ciao Andrea.
Ho un quesito che riguarda i campioni appaiati.
Abbiamo due serie:
5,7,4,8 e 6,7,5,9
Indicano rispettivamente i voti di 4 studenti nel primo e nel secondo quadrimetre.
Il quesito chiede se al livello del 5% si può ritenere che ci sia un miglioramento.
Cosa devo fare?
Ciao Elena.
Tu stai facendo un test di ipotesi in cui contrapponi l’ipotesi nulla H0 che sostiene che non vi sia evidenza di miglioramento.
In tale situazione la media delle differenze sarebbe pari a zero.
H0: media diff = 0
Contro l’ipotesi alternativa H1 che sostiene l’evidenza di una miglioramento.
In tale situazione la media delle differenza (tra il valore finale e quello iniziale) sarebbe maggiore di zero (positiva).
H1: media diff>0
Per risolvere il test che viene fatto con un livello di confidenza del 5% andrai a confrontare due valori del t-student.
Il valore associato al test che ha 3 gradi di liberta (gdl) in quanto si tratta di un test con dati dipendenti, quindi devi usare n-1 gdl e con area a destra pari a 0,05.
Questo significa che l’area a sinistra è 0,95.
Il secondo valore è la statistica test (t-test in questo caso), calcolato come il rapporto tra le media delle differenze e lo Standard Error associato alle differenze.
PROCEDIMENTO:
In primo luogo calcoli la serie delle differenze:
6-5=1, 7-7=0, 5-4=1, 9-8=1
A questo punto puoi calcolare la media delle differenze:
(1+0+1+1)/4=0,75
La varianza corretta dElle differenze risulta perciò:
(1^2+0^2+1^2+1^2)/3–0,75^2*4/3=0,25
Lo Standard Error delle differenze è pari a:
SE=radq(0,25/4)=0,25
La statistica test associata al dato campionario delle differenze è:
T-test=(media diff)/(SE diff)=0,75/0,25=3
Dobbiamo confrontare questo valore della statistica test con il t-student associato al test ovvero quello al livello 0,975 con 3 gradi di libertà:
t_(0,95; 3)=2,353
Essendo che il valore campionari è inferiore
Ciao, ho difficoltà nello svolgimento di questo quesito. Potresti aiutarmi? Grazie mille!
Testare l’ipotesi nulla che il n° medio di parassiti intestinali che possiedono le trote in 2 fiumi sia uguale. I campioni disponibili hanno queste caratteristiche:
Fiume 1: n° di pesci campionati = 22; media = 22,3; varianza= 5,4.
Fiume 2: n° pesci = 12; media = 24,8; varianza= 3,4.
Assumete che le assunzioni del test siano soddisfatte.
Ciao Nicolas
Per prima cosa dovresti verificare se dai dati campionari le varianze delle due popolazioni sono uguali o diverse.
Se sono diverse
Questo lo puoi fare con il test F della varianza
Poi applichi la formula per l’errore standard
Ti lascio un piccolo promemoria qui
https://andreailmatematico.it/statistica/campionamento-stia-e-test-di-ipotesi/confronto-tra-medie/
A questo punto calcoli la statistica test
Differenza medie/ SE
Dove SE Rappresenta l’errore standard
Attenzione che ora per decidere il test serve il t-student al 5%
Ti servono dunque i gradi di libertà (gdl)
Se le varianze le consideri uguali i gdl sono n1+n2 -2
Altrimenti devi usare una formula un po’ lunghetta
Occhio che sugli articoli devo correggere proprio questo punto
Perché ho impiegato un po’ a trovare la formula
Ciao Andrea!
Sul gruppo dell’esame di statistica stiamo tutti un po’ impazzendo perchè troviamo formule diverse… avrei un paio di domande dopo aver visto il tuo video corso se non è un disturbo:
ho seguito il video 3.1 media campionaria 1 in cui calcolavi l’ampiezza che avrebbe dovuto avere n con intervallo 95% e tempo medio ampiezza 10 minuti (l’es dell’alimentari che fa consegne a domicilio). Hai spiegato molto bene perchè si arriva ad elevare tutto alla seconda (e quindi infine si moltiplica z per 4). Noi abbiamo molti esercizi di questo tipo in cui al posto di “ampiezza” abbiamo “errore”. La formula rimane la stessa? Ampiezza ed errore sarebbero la stessa cosa?
Nel mio libro di statistica questo argomento è affrontato molto velocemente e parla di “errore” non di “ampiezza”, pensavo fosse la stessa cosa (la parte in mezzo della curva per intenderci), ma poi ho visto che la formula del libro è diversa .. n=Z^2*var/errore^2
Se riuscissi ad illuminarci su questo quesito ci faresti un enorme favore!!
Ciao Aurora
Tecnicamente
Sigma è la deviazione standard
Errore = z* sigma
Ampiezza = 2* errore
Quindi errore = 1/2*ampiezza
Colgo l’occasione per chiarire alcuni punti a proposito del tuo stiamo impazzendo che in questo ambito è proprio una condizione normale quando si comincia ad apprendere il mondo della statistica in maniera un po’ più avanzata.
Tieni conto che dietro il concetto di sigma si può nascondere un mondo
Ad esempio
Sigma (media camp) = sigma (pop) /radice(n)
Sigma (proporzione) = radice (p*(1-p)/n)
Poi trovi
Sigma (beta1)
Sigma (bera0)
Sigma (chi quadrato)
Sigma (R^2)
Per sigma intendi una deviazione standard di dati
Quando entri in un clima di inferenza puoi trova il sigma applicato a diversi oggetti
Come: medie, varianze, beta correlazioni eccetera
Quella formula che hai citato la trovi ad esempio
In intervalli di confidenza oppure test di ipotesi che usano la distribuzione normale come punto di riferimento nei conti
Grazie mille per la risposta! Quindi il tuo esercizio chiedeva di calcolare la numerosità del campione con intervallo di confidenza al 95% con ampiezza 10 minuti, l’esercizio che mi ritrovo spesso chiede di calcolare la numerosità del campione con intervallo di confidenza 90 % e margine di errore 0,05. La formula come cambia? (oltre a cambiare perchè nel tuo caso sigma media nell’esercizio che ho io è una proporzione) non moltiplico per due Z? Ho capito giusto? Non so se può aiutare ti scrivo l’esercizio: Il direttore di una banca vorrebbe stabilire la proporzione di depositanti che vengono pagati settimanalmente. Su un campione di 100 depositanti 30 affermano di esser pagati settimanalmente, A) si calcoli la stima con confidenza al 90 % della proporzione reale di quelli che vengono pagati settimanalmente B) Il direttore di banca vuole il 90% di confidenza che la sua stima sia corretta entro un intervallo di 0,05, intorno alla proporzione reale di depositari pagati settimanalmente quale sarà la dimensione del campione?
Ok ora è più chiaro
L’intervallo chiamiamolo
I = 2* z* sigma /radq(n)
Z = z(0,95) quello con area complessiva 0,95 sinistra che vale 1,645
Sigma = radq (p* (1-p))
p = 0,30= 30/100
Scrivendo più esteso
I = 2* z* radq(p*(1-p)/n)
Elevando alla seconda
I^2 = 4* z^2 * p * (1-p) / n
Da cui n
n= 4* z^2 * p * (1-p) / I