
In questo articolo parliamo della media, della varianza e della deviazione standard campionaria, ovvero che sono calcolate in un campione
INDICE
- 1 ESEMPIO: MEDIA, VARIANZA E DEVIAZIONE STANDARD
- 2 MEDIA CAMPIONARIA
- 3 VARIANZA CAMPIONARIA
- 4 VARIANZA DELLA POPOLAZIONE E VARIANZA CAMPIONARIA
- 5 PERCHE’ USIAMO UN CALCOLO DIVERSO?
- 6 DEVIAZIONE STANDARD CAMPIONARIA
- 7 Perché la Varianza Campionaria è “Timida”?
- 8 In sintesi: Perché proprio $n-1$?
- 9 La Guida Definitiva ai Correttori della Varianza
- 9.1 CASO 1: Estrazione con Reintegro (Bernoulli) – Ordine conta (o non conta)
- 9.2 CASO 2: Estrazione senza Reintegro – L’ordine conta (Disposizioni)
- 9.3 CASO 3: Estrazione senza Reintegro – L’ordine NON conta (Combinazioni)
- 9.4 CASO 4: Estrazione con Reintegro – L’ordine NON conta (Combinazioni con ripetizione)
- 9.5 Sintesi Finale per Davide
- 10 HAI QUALCHE DOMANDA SULLA MEDIA, VARIANZA E DEVIAZIONE STANDARD CAMPIONARIA?
- 11 IMPARA LA STATISTICA
ESEMPIO: MEDIA, VARIANZA E DEVIAZIONE STANDARD
Consideriamo un esempio molto semplice che riguarda un campione di 5 unità a cui viene chiesto quante sigarette fumano in un giorno.
I risultati sono riportati nella seguente tabella:
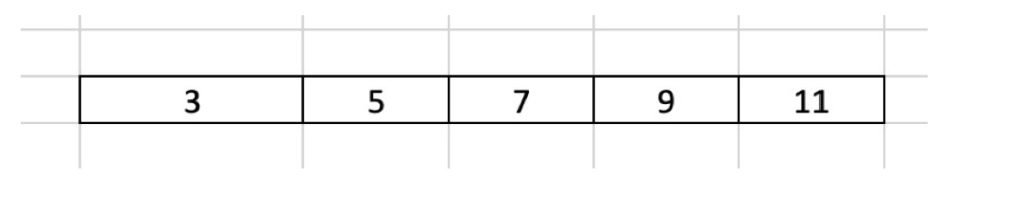
MEDIA CAMPIONARIA
Per calcolare la media campionaria facciamo la somma dei dati e dividiamo per il numero degli stessi.
Notiamo che questa procedura è assolutamente identica a quella per calcolare la media di una popolazione.
La formula che utilizziamo è la seguente:
$$ \bar x = \frac{\sum_{i=1}^n x_i}{n} $$
Inserendo i numeri a nostra disposizione scriviamo:
$$ \bar x = \frac{3+5+7+9+11}{5} = 7 $$
Con Excel le cose si fanno molto più semplici dal momento che basta che utilizziamo la formula:
$$ = \text{MEDIA (<dati>) } $$

VARIANZA CAMPIONARIA
Per ottenere la varianza campionaria possiamo citare due modi.
Il primo modo è quello di dividere la somma dei quadrati degli scarti dalla media per la numerosità del campione meno uno.
Cioè dividiamo la devianza delle x per n-1.
$$ s^2= \frac{ DEV(x) }{n-1} = \frac{ \sum_{i=1}^n (x_i – \bar x)^2}{n-1} $$
Notiamo bene che per indicarla abbiamo usato la lettera romana esse (s).
Inserendo i dati che conosciamo scriviamo:
$$ s^2= \frac{ (3-7)^2 + (5-7)^2 + (7-7)^2 + (9-7)^2 + (11-7)^2 }{5-1} = 10 $$
Il secondo modo che possiamo utilizzare è il seguente:
$$ s^2= \frac{ \sum_{i=1}^n x_i^2}{n-1} – (\bar x)^2 \cdot \frac{n}{n-1} $$
In questo caso scriviamo:
$$ s^2_C = \frac{3^2 + 5^2 +7^2 +9^2 +11^2}{5-1} – 7^2 \cdot \frac{5}{5-1} = 10 $$
Per calcolare la varianza campionaria con Excel risulta tutto molto semplice poiché basta inserire la formula:
$$ = \text{VAR.C ( <dati> ) } $$

VARIANZA DELLA POPOLAZIONE E VARIANZA CAMPIONARIA
Facciamo chiarezza una volte per tutte sulla differenza che intercorre tra il calcolo della varianza riferito ad una popolazione e il calcolo della varianza campionaria.
La varianza intesa in senso classico (varianza della popolazione) è la media dei quadrati degli scarti e si calcola come segue:
$$ \sigma ^2 = \frac{\sum_{i=1}^n (x_i – \bar x)^2}{n} $$
Notiamo bene che per indicarla abbiamo utilizzato la lettera greca sigma (𝜎) elevata alla seconda.
Oppure potrebbe anche essere vista come la media dei quadrati meno il quadrato della media:
$$ \sigma ^2 = \frac{\sum_{i=1}^n x_i^2}{n} – (\bar x)^2 $$
Notiamo pure che per fare una distinzione tra questa e la varianza della popolazione abbiamo usato la lettere greca “σ” in contrapposizione alla lettera romana “s” utilizzata per la varianza campionaria.
Notiamo pure che per fare una distinzione tra questa e la varianza della popolazione abbiamo usato la lettere greca “σ” in contrapposizione alla lettera romana “s” utilizzata per la varianza campionaria.
Quest’ultima invece viene calcolata nei modi che abbiamo presentato sopra:
$$ s^2= \frac{ \sum_{i=1}^n (x_i – \bar x)^2}{n-1} = \frac{ \sum_{i=1}^n x_i^2}{n-1} – (\bar x)^2 \cdot \frac{n}{n-1} $$
Per ottenere la varianza campionaria a partire dalla varianza della popolazione moltiplichiamo quest’ultima per n e la dividiamo per n–1.
$$ s^2 = \sigma ^2 \cdot \color{blue}{\frac{n}{n-1}} $$
Facendo questa operazione otteniamo infatti che:
$$ s^2 = \sigma ^2 \cdot \color{blue}{\frac{n}{n-1}} = \frac{\sum_{i=1}^n (x_i – \bar x)^2}{n} \cdot \color{blue}{\frac{n}{n-1}} = \frac{\sum_{i=1}^n (x_i – \bar x)^2}{n-1} $$
Che è la nostra varianza campionaria
PERCHE’ USIAMO UN CALCOLO DIVERSO?
Se abbiamo un modo per calcolare la varianza di una popolazione di dati perché cambiare questa formula quando siamo di fronte ad un campione?
Possiamo trovare la risposta a questa domanda nella più ampia teoria dell’inferenza.
In particolare nella parte che riguarda la correttezza degli stimatori.
Per farla breve supponiamo di avere una popolazione di 10 elementi e consideriamo tutti i possibili campioni con ripetizione e ordinati con 3 elementi di questa popolazione.
(cosa non affatto facile da farsi a mano poiché il numero di campioni sarebbe abbastanza alto)
$$ \text{n. campioni} = 10^3 = 1.000 $$
Comunque se calcoliamo la varianza di ogni singolo campione (1000 varianze) e poi andiamo a fare la media delle varianze non troviamo la varianza della popolazione.
Se invece consideriamo le varianze campionarie come intese in questo articolo, ecco che la loro media coincide magicamente con la vera varianza della popolazione.
Svelato questo arcano passiamo al calcolo della deviazione standard campionaria.
DEVIAZIONE STANDARD CAMPIONARIA
La deviazione standard campionaria è la radice quadrata della varianza campionaria:
$$ s = \sqrt{s^2} = \sqrt{ \frac{\sum_{i=1}^n (x_i – \bar x)^2}{n-1} } = \sqrt{ \frac{ \sum_{i=1}^n x_i^2}{n-1} – (\bar x)^2 \cdot \frac{n}{n-1}} $$
Con i nostri dati scriviamo:
$$ s = \sqrt{10} = 3,16 $$
Con il foglio elettronico possiamo scrivere:
$$ = \text{RADQ( <varianza> )} $$
Dove per varianza intendiamo il calcolo di prima.
Oppure se vogliamo selezionare direttamente i dati andiamo a scrivere:
$$ = \text{DEV.ST.C( <dati> )} $$

Perché la Varianza Campionaria è “Timida”?
In risposta al commento di Davide: lo stimatore è non distorto solo se, “facendo la media” di infinite varianze campionarie, otteniamo esattamente la varianza della popolazione.
Il motivo per cui dividere per $n$ fallisce è sottile: la varianza campionaria usa la media campionaria ($\bar{x}$) come punto di riferimento, non la vera media della popolazione ($\mu$). Poiché $\bar{x}$ è calcolata proprio a partire dai dati del campione, essa si posiziona sempre al “centro esatto” di essi, rendendo gli scarti artificialmente più piccoli. È come se i dati si sentissero “troppo a casa” con la loro media, mostrandosi meno variabili di quanto siano realmente.
Vediamolo con i numeri esatti del tuo esempio.
1. La Popolazione “Vera”
Immaginiamo una popolazione finita: $P = \{1, 2, 3\}$.
- Media della popolazione ($\mu$): $\frac{1+2+3}{3} = \mathbf{2}$
- Varianza della popolazione ($\sigma^2$):$$\sigma^2 = \frac{(1-2)^2 + (2-2)^2 + (3-2)^2}{3} = \frac{1+0+1}{3} = \mathbf{\frac{2}{3} \approx 0.667}$$
2. L’Esperimento: Estrazione dei Campioni ($n=2$)
Estraiamo tutti i $3^2 = 9$ campioni possibili (con reinserimento) e calcoliamo per ognuno la varianza “distorta” ($s^2_{\text{dist}}$), ovvero quella che divide per $n$.
| Campione | Media (xˉ) | Calcolo Varianza (/n) | sdist2 |
| (1, 1) | 1.0 | $[(1-1)^2 + (1-1)^2] / 2$ | 0 |
| (1, 2) | 1.5 | $[(1-1.5)^2 + (2-1.5)^2] / 2$ | 0.25 |
| (1, 3) | 2.0 | $[(1-2)^2 + (3-2)^2] / 2$ | 1.0 |
| (2, 1) | 1.5 | $[(2-1.5)^2 + (1-1.5)^2] / 2$ | 0.25 |
| (2, 2) | 2.0 | $[(2-2)^2 + (2-2)^2] / 2$ | 0 |
| (2, 3) | 2.5 | $[(2-2.5)^2 + (3-2.5)^2] / 2$ | 0.25 |
| (3, 1) | 2.0 | $[(3-2)^2 + (1-2)^2] / 2$ | 1.0 |
| (3, 2) | 2.5 | $[(3-2.5)^2 + (2-2.5)^2] / 2$ | 0.25 |
| (3, 3) | 3.0 | $[(3-3)^2 + (3-3)^2] / 2$ | 0 |
| MEDIA | Somma / 9 | 0.333 ($1/3$) |
Il verdetto: La media delle varianze campionarie ($0.333$) è la metà della vera varianza ($0.667$). Dividendo per $n$, abbiamo ottenuto una stima che “sottostima” sistematicamente la realtà.
3. La Magia della Correzione ($n-1$)
Per correggere questa distorsione, applichiamo la Correzione di Bessel. Invece di dividere per $n=2$, dividiamo per $n-1 = 1$.
Riprendiamo il valore medio ottenuto sopra ($1/3$) e applichiamo il fattore di correzione:
$$\text{Varianza Corretta} = s^2_{\text{dist}} \cdot \left( \frac{n}{n-1} \right)$$
$$\text{Varianza Corretta} = \frac{1}{3} \cdot \left( \frac{2}{1} \right) = \mathbf{\frac{2}{3}}$$
Il risultato ora coincide perfettamente con la vera varianza della popolazione!
In sintesi: Perché proprio $n-1$?
Quando calcoliamo la media campionaria $\bar{x}$, “sprechiamo” un’informazione. I dati non sono più liberi di variare totalmente: se conosciamo la media e $n-1$ valori, l’ultimo valore è già obbligato (determinato).
Abbiamo perso un Grado di Libertà. Dividere per $n-1$ non è altro che il modo matematico per compensare quel “senso di vicinanza” artificiale tra i dati e la loro media campionaria, restituendo alla varianza la sua vera ampiezza.
1. Il punto di partenza: La scomposizione dello scarto
Per capire come la varianza campionaria si “piega” verso la propria media, dobbiamo guardare alla distanza tra ogni dato $X_i$ e la media vera della popolazione $\mu$. Possiamo scrivere questa distanza inserendo artificialmente la media del campione $\bar{X}$:
$$(X_i – \mu) = (X_i – \bar{X}) + (\bar{X} – \mu)$$
Se eleviamo al quadrato entrambi i membri, otteniamo:
$$(X_i – \mu)^2 = [(X_i – \bar{X}) + (\bar{X} – \mu)]^2$$
$$(X_i – \mu)^2 = (X_i – \bar{X})^2 + (\bar{X} – \mu)^2 + 2(X_i – \bar{X})(\bar{X} – \mu)$$
2. Sommare le visioni: Dalla singola unità al campione
Ora sommiamo per tutte le $n$ unità del campione ($\sum_{i=1}^n$). La somma è un operatore lineare che rivela una struttura profonda:
$$\sum (X_i – \mu)^2 = \sum (X_i – \bar{X})^2 + \sum (\bar{X} – \mu)^2 + 2(\bar{X} – \mu) \sum (X_i – \bar{X})$$
Qui accade un fatto matematico cruciale: la somma degli scarti dalla propria media campionaria, $\sum (X_i – \bar{X})$, è sempre zero per definizione. Di conseguenza, il terzo termine (il doppio prodotto) svanisce, lasciandoci con:
$$\sum (X_i – \mu)^2 = \sum (X_i – \bar{X})^2 + n(\bar{X} – \mu)^2$$
Possiamo isolare la somma dei quadrati degli scarti che usiamo per la varianza campionaria:
$$\sum (X_i – \bar{X})^2 = \sum (X_i – \mu)^2 – n(\bar{X} – \mu)^2$$
3. Il Valore Atteso: Verso la Verità Statistica
Per verificare se lo stimatore è corretto, dobbiamo calcolare il suo Valore Atteso $E[\cdot]$. Applichiamo l’operatore $E$ a entrambi i membri dell’equazione precedente:
$$E\left[\sum (X_i – \bar{X})^2\right] = E\left[\sum (X_i – \mu)^2\right] – E\left[n(\bar{X} – \mu)^2\right]$$
Per linearità, portiamo la somma fuori dal valore atteso:
$$E\left[\sum (X_i – \bar{X})^2\right] = \sum E[(X_i – \mu)^2] – n E[(\bar{X} – \mu)^2]$$
Ora ricordiamo le definizioni fondamentali:
- $E[(X_i – \mu)^2] = \sigma^2$ (è la definizione stessa di varianza della popolazione).
- $E[(\bar{X} – \mu)^2] = Var(\bar{X})$ (è la varianza della media campionaria, che sappiamo essere $\frac{\sigma^2}{n}$).
Sostituiamo questi valori:
$$E\left[\sum (X_i – \bar{X})^2\right] = \sum_{i=1}^n \sigma^2 – n \left( \frac{\sigma^2}{n} \right)$$
$$E\left[\sum (X_i – \bar{X})^2\right] = n\sigma^2 – \sigma^2$$
$$E\left[\sum (X_i – \bar{X})^2\right] = (n – 1)\sigma^2$$
4. La Conclusione: La necessità del Grado di Libertà
La dimostrazione ci urla il risultato finale: se sommiamo i quadrati degli scarti dalla media del campione, in media otteniamo $(n-1)$ volte la varianza vera, non $n$ volte.
Se definissimo la varianza campionaria dividendo per $n$:
$$E\left[ \frac{\sum (X_i – \bar{X})^2}{n} \right] = \frac{n-1}{n}\sigma^2 < \sigma^2$$
Otterremmo uno stimatore distorto che “sottostima” sistematicamente la realtà.
Per ottenere uno stimatore non distorto (unbiased), dobbiamo annullare quel termine $(n-1)$. Ecco perché dividiamo per $n-1$:
$$s^2 = \frac{1}{n-1} \sum_{i=1}^n (X_i – \bar{X})^2 \implies E[s^2] = \frac{1}{n-1} (n-1)\sigma^2 = \mathbf{\sigma^2}$$
In questa sottrazione, $n-1$, risiede la libertà ritrovata dei dati: avendo usato i dati una volta per calcolare la media $\bar{X}$, abbiamo “pagato” un prezzo di un grado di libertà. Dividere per $n-1$ è l’unico modo per riportare lo specchio del campione alla stessa grandezza della realtà della popolazione.
La Guida Definitiva ai Correttori della Varianza
Ciao Davide, per rispondere al tuo dubbio dobbiamo distinguere quattro scenari. In ognuno di essi, la media delle varianze che osservi nel campione ($E[s^2]$) è influenzata da due fattori: la libertà del campione (il fattore $n$) e la struttura dell’universo (il fattore $N$).
Ecco la mappa completa per ritrovare la varianza della popolazione $\sigma^2$ partendo dai campioni.
CASO 1: Estrazione con Reintegro (Bernoulli) – Ordine conta (o non conta)
Questo è il modello standard della statistica. Ogni estrazione è indipendente. Qui la distinzione tra “ordine conta” e “non conta” svanisce perché le frequenze naturali dei campioni bilanciano perfettamente il calcolo.
- Relazione con la varianza non corretta ($s^2_{dist}$, divisa per $n$):$$\sigma^2 = E[s^2_{dist}] \cdot \left( \frac{n}{n-1} \right)$$
- Relazione con la varianza corretta ($s^2$, divisa per $n-1$):$$\sigma^2 = E[s^2]$$
- Perché: In questo mondo infinito (o con reintegro), il correttore di Bessel ($n-1$) è l’unica chiave necessaria per sbloccare la verità.
CASO 2: Estrazione senza Reintegro – L’ordine conta (Disposizioni)
In questo mondo finito, l’universo si rimpicciolisce a ogni estrazione. I dati sono legati da una “parentela” (covarianza negativa) perché non possono ripetersi.
- Relazione con la varianza non corretta ($s^2_{dist}$):$$\sigma^2 = E[s^2_{dist}] \cdot \left( \frac{n}{n-1} \right) \cdot \left( \frac{N-1}{N} \right)$$
- Relazione con la varianza corretta ($s^2$):$$\sigma^2 = E[s^2] \cdot \left( \frac{N-1}{N} \right)$$
- Perché: Qui il campione tende a sovrastimare la varianza della popolazione perché cerca di colpire la quasi-varianza ($S^2$). Dobbiamo “sgonfiare” il risultato con il fattore $(N-1)/N$ per tornare alla scala della popolazione finita.
CASO 3: Estrazione senza Reintegro – L’ordine NON conta (Combinazioni)
È il caso che hai sollevato tu: solo 3 campioni $\{1,2\}, \{1,3\}, \{2,3\}$.
- Le Formule: Sono identiche al Caso 2.
- Perché: Anche se i campioni sono numericamente meno (3 invece di 6), ogni campione “senza ordine” pesa esattamente quanto la somma dei suoi corrispettivi “ordinati”. La media non cambia. La scomposizione algebrica non risente della cronologia delle estrazioni, ma solo della loro composizione.
CASO 4: Estrazione con Reintegro – L’ordine NON conta (Combinazioni con ripetizione)
Questo è il “mondo artificiale”. Qui estraiamo con ripetizione ma decidiamo che $\{1,2\}$ e $\{2,1\}$ siano lo stesso evento, e che $\{1,1\}$ abbia lo stesso peso di $\{1,2\}$. È un caso raro nella pratica, ma matematicamente affascinante.
- Relazione con la varianza non corretta ($s^2_{dist}$):$$\sigma^2 = E[s^2_{dist}] \cdot \left( \frac{2(N+1)}{N} \right) \quad (\text{per } n=2)$$
- Relazione con la varianza corretta ($s^2$):$$\sigma^2 = E[s^2] \cdot \left( \frac{N+1}{N} \right)$$
- Perché: In questo scenario, dando lo stesso peso ai doppi (come $\{1,1\}$) che hanno varianza zero, la media campionaria della varianza crolla drasticamente ($0.5$ nel nostro esempio). Il fattore di correzione deve essere molto più “aggressivo” ($(N+1)/N$) per compensare l’eccesso di peso dato agli elementi statici.
Sintesi Finale per Davide
| Caso | Relazione tra σ2 e Media Varianze Corrette (E[s2]) |
| Con Reintegro (Standard) | $\sigma^2 = E[s^2]$ |
| Senza Reintegro (Tutti i casi) | $\sigma^2 = E[s^2] \cdot \frac{N-1}{N}$ |
| Con Reintegro (Senza Ordine) | $\sigma^2 = E[s^2] \cdot \frac{N+1}{N}$ |
Conclusione:
Davide, come vedi, la formula della varianza non è un dogma assoluto, ma un organismo che reagisce al modo in cui interroghi la realtà. Se il tuo universo è “aperto” (reintegro), la varianza campionaria corretta è la verità. Se il tuo universo è “chiuso” (senza reintegro), quella stessa varianza è solo un gradino che ti porta alla quasi-varianza, e devi fare un piccolo passo indietro per ritrovare la varianza descrittiva della popolazione.
HAI QUALCHE DOMANDA SULLA MEDIA, VARIANZA E DEVIAZIONE STANDARD CAMPIONARIA?
Se questo articolo ha stimolato in te qualche domanda scrivila nei commenti.
Con le tue domande puoi aiutare molti altri utenti con le tue stesse difficoltà.
IMPARA LA STATISTICA
Comincia un fantastico viaggio alla scoperta di questa affascinante materia partendo da zero.
Si comincia dalla statistica descrittiva, passando per le probabilità si arriva all’inferenza.
Comincia subito il tuo percorso e migliora le tue abilità.
39 risposte
Ciao Andrea. Tra le esercitazioni in preparazione all’esame, c’è questa a cui non riesco a dare una risposta:
“Sapendo che una distribuzione ha primo quartile pari a 15 e range interquartile pari a 0, che valori avranno la varianza e la media?”
Grazie e buona giornata!
Ciao Elena,
Grazie per la domanda 😉
Il range interquartile è la differenza tra il terzo e il primo quartile
Conoscendo il fatto che questa vale zero e che il primo interquartile vale 15 l’unica cosa che possiamo concludere con certezza è che anche il terzo quartile vale 15.
Ovviamente siccome la mediana è certamente compresa tra il primo e il terzo quartile la mediana vale certamente 15.
Non possiamo concludere niente però circa la varianza e la media.
Questi valori infatti vengono calcolati tenendo conto di tutti i dati (del campione o della popolazione.
Diversamente se la domanda avesse dato come dato iniziale: “il range dei dati vale zero con il terzo quartile che vale 15”
(Con il range dei dati intendiamo la differenza tra il max e il min della distribuzione).
In questo caso potevamo certamente concludere che
Massimo=minimo=primo quartile = mediana = terzo quartile
Questi sono certamente uguali anche alla media.
Essendo che tutti i dati hanno lo stesso valore la varianza vale certamente zero.
ciao andrea!! mi trovo di fronte un esercizio in cui sono presentate le esportazioni e le importazioni dei paesi UE calcolate in milioni di euro. l’esercizio mi dice come cambierebbe il valore della media e della varianza se esprimiamo i valori in euro. Cambierebbe il cv? la cosa che non riesco a capire è che i dati sono già espressi in euro, e quindi non so come muovermi! grazie
Ciao Salvatore 😉
Interessante domanda.
Da quel che ho capito i dati di cui disponi sono in MILIONI di euro.
Quindi se li devi esprimere in euro li devi moltiplicare per 1 milione ovvero per 10^6.
In questo caso la media è un operatore lineare che risente della costante moltiplicativa (oltre a quella additiva).
La media si moltiplicherebbe per 10^6.
La varianza risente invece del quadrato della costante moltiplicativa, dunque si moltiplica per 10^12.
Come cambia il CV?
IL CV è definito come il rapporto tra la deviazione standard e la media.
Nel nostro caso la deviazione standard è la radice quadrata della varianza.
Perciò anche la deviazione. st. (come la media si moltiplica per 10^6.
Dunque il nuovo CV è:
CV’=(dev.st’)/(media’)=(10^6·dev.st)/(10^6·media)=dev.st/media=CV.
Il CV dunque non cambia copia quando ci troviamo di fronte ad una trasformazione lineare in cui c’è solamente la variabile moltiplicativa.
A questo proposito vorrei farti un esempio in cui abbiamo una completa trasformazione lineare.
Prendi in esame questo caso.
Sappiamo che la media e la varianza di una certa variabile X siano rispettivamente 5 e 4.
Se la varianza vale 4 significa la dev. st. vale 2, ovvero la radice di 4.
Il CV(x)=5/2=2,5
se trasformiamo la variabile X in 3X-1 come cambiano media, varianza, dev.st e CV?
La media è un’operatore certamente lineare, dunque:
M(3X-1)=3M(X)-1=3·5-1=14
La varianza risente del quadrato della costante moltiplicativa, dunque:
VAR(3X-1)=3^2·VAR(X)=9·VAR(X)=9·4=36
il CV è la radice quadrata della varianza dunque:
CV(3X-1)=radq(36)=6
tale valore è proprio la costante moltiplicativa per la dev.st di X.
DEV.ST(3X-1)=3·DEV.ST(X)=3·2=6
il CV di 3X-1 diventa:
CV(3X-1)=DEV.ST(3X-1)/MEDIA(3X-1)=6/14=0,4285
Quando c’è anche una costante additiva il CV cambia certamente.
Ciao Andrea, mi sto preparando per un esame e mi sono imbattuta in questa domanda a cui non riesco a trovare risposta, “In un universo statistico la varianza di una variabile statistica è 30 e la media della varianza campionaria è 29,7. Da quante unità statistiche sono costituiti i campioni?” npn sono sicura di cosa intenda per unità statistiche e non so come procedere. Ti ringrazio in anticipo!
Ciao Elena,
Grazie della bella domanda.
Partiamo dal fatto che la varianza di una popolazione è la media del quadrato degli scarti su tutte le unità della popolazione:
VARpop = ∑s²/n
Mentre la media della popolazione è la media dei quadrati degli scarti ponderata per n-1
VARcamp = ∑s²/(n-1)
Facendo qualche piccola semplificazione i dati a tua disposizione sono:
VARpop = ∑s²/n = 30
VARcamp = ∑s²/(n-1)=29,7
Ricavando dalle equazioni la sommatoria degli scarti otteniamo che:
∑s² = 30n
∑s²=29,7(n-1)
Eguagliando i termini delle due equazioni otteniamo che:
30n=29,7(n-1)
Risolvendo l’equazione di primo grado abbiamo che:
30n = 29,7n – 29,7
0,3n = 29,7
n = 29,7/0,3 = 99
Un altro modo di risolvere il problema è il seguente:
Sappiamo che la media della varianza campionaria è ottenuta moltiplicando la varianza della popolazione per n e dividendola per (n-1), dunque:
Media(VARcamp) = VARpop ·n(n-1)
Inserendo i dati abbiamo che:
29,7 = 30·n/(n-1)
Da cui otteniamo l’equazione di prima:
30n=29,7(n-1)
Ottenendo dunque che l’ampiezza del capione è pari a 99.
Ti ringrazio ho capito il procedimento, però non capisco perché nel calcolo il – 29,7 diventi positivo, non dovrebbe essere
30n – 29,7n = – 29,7
0,3n = -29,7
n = – 99?
anche se poi porterebbe appunto un numero negativo, il che non ha senso….
Giusta osservazione Elena
In effetti è meglio procedere con questo ragionamento.
La media delle varianza campionarie è 29,7.
Questa è stata ottenuta sommando le varianze dei campioni (non corrette) e dividendole per N (numero dei campioni).
Ora sappiamo la media delle varianza dei campioni non è la vera varianza.
Per ottenere questa è infatti necessario moltiplicarla per il numero di elementi del campione n e dividerla per (n-1)
Da qui abbiamo che:
Media Var(camp) * n / (n-1) = var.(pop)
Dunque inserendo i numeri:
29,7*n/(n-1) = 30
Otteniamo perciò un’equazione di primo grado:
29,7n = 30(n-1)
29,7n = 30n-30
0,3n = 30
n=30/0,3 = 100
Dunque gli elementi del campione sono 100.
Andrea ti chiedo aiuto per questo quiz… mi sto affacciando adesso alla materia!
Per un campione di numerosità N estratto da una popolazione con distribuzione di media E(X) e
varianza VAR(X) si ha che
A Il Rapporto E(X)/Var(X) è distribuito come una t di Student
B Il Rapporto E(X)/Var(X) è distribuito come una F di Fisher
C Il Rapporto E(X)/Var(X) è distribuito come un Chi quadrato
Ciao Giovanni
Grazie per la domanda
Devo ammettere che si tratta di una domanda molto tosta a cui non saprei rispondere
Poiché è la prima volta che sento di questa possibile distribuzione
Tuttavia potrei azzardare che si tratta di una t student
In quanto sia la variabile fisher che il chi quadrato assumono valori strettamente positivi.
Quindi sembrerebbe logico pensare che tale rapporto possa assumere anche valori nulli o negativi (dal momento che anche la media può essere nulla o negativa)
Buonasera Andrea,
Ho un esercizio di statistica che non riesco a risolvere:
“si effettuano 50 lanci con una moneta non truccata. Si vuole sapere qual è la probabilità che la media delle teste uscite sia minore di due volte lo scarto quadratico medio.” (risultato p>0,75).
Per favore, può gentilmente aiutarmi?
La ringrazio.
Cordiali saluti
Tania
Ciao Tania, grazie per la domanda.
Premetto che ho letto molte volte il testo
Ma non sono sicuro che questa interpretazione corretta…
Noi vogliamo che la media sia minore di 2 volte sqm.
Ricordiamo anzitutto che siamo di fronte ad una distribuzione binomiale.
In tale distribuzione i parametri sono n e p.
n = numero di lanci = 50 (lo conosciamo)
p = probabilità = 0,50 (noto poiché il dado è regolare)
Credo che il problema sia riconducibile al teoremi Chebicev
che ci dice che La probabilità che la variabile x differisca di una certa quantità k sia pari a
1-1/k^2
Nel nostro caso k è il doppio della deviazione standard.
Nella distribuzione binomiale la del. st si calcola come segue:
devst =radq( n*p*(1-p) )=radq( 50*0,50*(1-0,50)) = 3,5355
Ora se vogliamo k è il doppio di tale quantità, ovvero =
k = 7,071
Ora dunque p = 1 – 1/7,071^2 = 0,8585
Non è lo 0,75 del risultato, ma di altre procedure on saprei.
Dal momento che ho già provato altre tre strade ma molto incoerenti con la richiesta.
Buonasera Andrea;
Ho un esercizio di statistica che non riesco a risolvere:
sia X una variabile casuale normale con media 3 e varianza 4, Quanto vale il quantile di livello x=0.13?
Grazie in anticipo
Ciao Roberto.
Il tuo obiettivo è quello di cercare il quantile 0,13 della distribuzione normale X con media 3 e varianza 4.
Per calcolarlo usiamo la seguente formula di standardizzazione:
x_0,13 = mu + z_0,13·sigma
Dove:
x_0,13 è il quantile 0,13 della normale X
mu = è la media di x, ovvero 3
sigma è la deviazione standard della x, che è la radice di 4, ovvero 2
La cosa più rognosa è dunque cercare il quantile 0,13 della distribuzione normale z_0,13=???
Se non disponi di programmi elettronici con excel ti consiglio dunque di ricercare sulle tavole il valore di z associato a questo quantile.
Certamente tale valore è negativo, quindi se hai delle tavole di z con valori negativi meglio ancora.
Se le possiedi devi leggere all’interno delle tavole il valore 0,13 oppure quello che si avvicina di più.
Ad esempio nelle mie tavole vedo che 0,13 è compreso tra 0,1314 e 0,1292.
Il primo dei due valori è associato al valore di z pari a -1,12, mentre il secondo a -1,13.
Potresti ad esempio decidere di prendere il valore di z centrale, come ad esempio -1,125.
Oppure di usare l’interpolazione lineare per essere più preciso.
Oppure ancora di presedere semplicemente il valore che tra i due si avvicina di più ovvero -1,13.
Comunque sia il risultato non cambierà più di molto.
Nel caso tu disponessi di tavole con valori positivi dovresti cercare all’interno delle tavole il complementare a 0,13 ovvero 0,87.
Questo perché quel 0,13 rappresenta l’area della funzione a sinistra. e di conseguenza l’area a destra è quella complementare.
Chiaramente bisognerai prendere i valori di z associati a 0,87.
Il binomio di prima si ripete con i valori 1,12 e 1,13.
Supponiamo di prendere il valore centrale tra i due, ovvero 1,125.
A questo punto dovremo cambiare il segno, perché stiamo ragionamento sulla parte sinistra della normale.
il nostro valore standardizzato sarà dunque -1,125.
Quest’ultimo valore che abbiamo trovato è il quantile a livello 0,13 SULLA NORMALE.
Possiamo anche indicarlo con : z_0,13 = -1,125
A questo punto per trovare il quantile di livello 0,13 sulla nostra X usiamo la seguente formula:
x_0,13 = mu + z_0,13·sigma
Sostituendo i valori abbiamo che:
x_0,13 = 3 – 1,125·2 = 0,75
Buonasera Andrea, ho un problema che non riesco a capire, ho anche la soluzione ma non capisco.
Testo: Un gioco consiste nel lanciare una moneta e nel generare un numero casuale Y tra zero e uno. La vincita è 2Y se compare testa, 1 se compare croce. Calcolare la vincita attesa.
Seguendo la soluzione viene calcolata la variabile aleatoria indicatrice e la variabile aleatoria speculare. I(t) se esce testa, I(-t) se esce croce
Viene quindi calcolata la vincita V=2Y I(t)-I(-t)
Poi viene calcolato il valore atteso, il valore medio della variabile aleatoria distribuita uniformemente ed il risultato finale E[V] viene zero.
non capisco come sia possibile.
Mi perdo già al primo passaggio perchè sommerei i valori anzichè sottrarli
Aspetta mi sto perdendo anche io leggendo il testo, sicura che sia proprio quello che hai scritto (letteralmente)?
https://boccignone.di.unimi.it/SAD_2017_files/esame_2017-10-30_sol.pdf
Si riferisce all esercizio sulla seconda pagina immagino
Secondo me c’è un errore nel testo
La vincita è 2Y
Mentre ci dovrebbe essere scritto si perde uno se esce croce
In questo caso la perdita media sulla croce sarebbe 1/2
Ovvero 1*0,5
Dove 1 rappresenta la perdita e 0,5 la probabilità che esca croce
Ragionando in termini vittoria media sarebbe -1*0,5=-1*1/2 (se la moneta non è truccata)
Quanto alla vincita con la testa le cose sono un po’ più complesse perche si tratta di generare un numero causale tra 0 e 1.
Quante possibilità avresti?
La risposta è infinite!
Se generi 0,1 la tua vincita media su tutto il gioco sarebbe
2*0,1*1/2-1*1/2=-0,4
Se generi 0,2 avresti
2*0,2*1/2-1*1/2=-0,3
Se generi 0,3 avresti
2*0,3*1/2-1*1/2=-0,2
Se generi 0,4 avresti
2*0,4*1/2-1*1/2=-0,1
Se generi 0,5 avresti
2*0,5*1/2-1*1/2=0
Se generi 0,6 avresti
2*0,6*1/2-1*1/2=0,1
Se generi 0,7 avresti
2*0,7*1/2-1*1/2=0,2
Se generi 0,8 avresti
2*0,8*1/2-1*1/2=0,3
Se generi 0,2 avresti
2*0,9*1/2-1*1/2=0,4
Se il tuo numero può avere solo due cifre decimali facendo la media di questi valori ottieni zero
Ora considera che potresti generare cifre con due decimali
0.01, 0.02, 0.03, 0.04,…, 9,99
Oppure con tre cifre decimali
0.001, 0.002, 0.003, 0.004,…, 9,999
O con 4,5,6,10000 cifre decimali
Da qui hai la necessità di avere una distribuzione continua che è uniforme
La media di una distribuzione uniforme è (a+b)/2
a corrisponde allo 0
b corrisponde a 1
Il valore medio che quindi puoi generare è
(0+1)/2=1/2=0,5
La vincita media è dunque
P(T)*V(T)+P(C)*V(C)
P(T) =0,5 è la prob che esca testa
V(T) è la vittoria media in caso di testa
Che è pari a 2*valore medio tra 0e1
= 2*1/2=1
P(C) è la prob di croce=0,5 (moneta non truccata
V(C) = -1 (vittoria negativa o perdita se esce croce) che è anche il valore medio stesso di sconfitta dal momento che è sempre quello
Sostituisci i valori e trovi zero
Grazie mille! Davvero gentilissimo!!! Sisi il testo era proprio quello
Buonasera, innanzitutto volevo ringraziarti per le tue spiegazioni sempre molto chiare e precise. Ho scoperto da poco il tuo sito e sono sollevata perché ora sono dove posso studiare per il mio esame di statistica!
Ho un dubbio, che forse sembrerà un po’ sciocco, ma sono davvero una principiante in questa materia.
In un esercizio sul test t di Studenti mi viene chiesto di calcolare la statistica test per campioni indipendenti, ma non mi è data la deviazione standard campionaria quindi deduco che la debbo calcolare in questo modo:
– elevo al quadrato la differenza tra ogni valore del campione e la media del campione
– calcolo S facendo la radice quadrata del rapporto tra il valore trovato prima e i gradi di libertà -1
Il risultato però non mi esce e ho provato a fare i calcoli anche con Excel… sbaglio metodo? Questo procedimento mi pare un po’ lungo: è corretto oppure ne esiste un altro più veloce (considerando che poi devo fare lo stesso per l’altro campione…)?
Grazie mille in anticipo per la risposta, buona serata.
Barbara
Ciao Barbara
Grazie per la domanda
La procedura che hai indicato è corretta tranne la divisione
Dividi quella somma di quadrati degli scarti non per gdl-1, ma per n-1
Dove n è il numeri di dati del campione
Per capirlo meglio considera sempre esempi semplici
Hai 3 dati
1,3,5
La media è 3
La varianza campionaria è
Modo 1
[(1-3)^2+(3-3)^2+(5-3)^2]/(3-1)=4
Oppure
(1^2+3^2+5^2)/2 – 3^2 *3/2= 4
Se fai il calcolo su EXCEL puoi anche usare la formula
DEV.ST.C.(dati)
Ora è chiaro che se fai a mano i calcoli è più difficile è molte volte porta all’abbandono della materia
Se devi per forza fare a mano i calcoli ti consiglio questo.
Fai l’esercizio su meno dati
Fai tre quattro esercizi solo su quattro dati e controlla con la formula di EXCEL
Poi inserisci un dato in più e fai 3/4 esercizi con 5 dati
Poi fallo con sei dati
Anche se sembra una procedura ripetitiva e priva di significato ti aiuterà a inserirti GRADUALMENTE verso il mondo dei calcoli matematici
Usare gradienti con minore difficoltà poi la mente si abitua e si tempra
Buonasera Andrea,
ho una domanda forse stupida, nella formula della varianza campionaria vediamo all’interno della sommatoria (xi-media)^2 come posso avere la formula che mi è capitato di vedere dove nella sommatoria rimane xi^2 -media^2 (con la media fuori dalla sommatoria)?
Grazie in anticipo!
Ciao Edoardo
In statistica su distinguono due varianze
Se hai tutti i dati della popolazione le formule che puoi utilizzare sono:
VAR = somma(xi – media)^2 /n
Si tratta della media dei quadrati degli scarti
In alternativa puoi fare
VAR = somma (xi)^2 – media^2
Se però NON possiedi tutti i dati della popolazione e hai a che fare con un campione allora devi calcolare la varianza corretta
Modo 1
VAR.C = somma(xi – media)^2 /(n-1)
Anziché dividere per n dividi per n-1
Modo2
VAR = somma (xi)^2/(n-1)- media^2*n/(n-1)
Modo 3
Prendi la varianza come se la calcoli sulla popolazione e la moltiplichi per n/(n-1)
VAR.C= VAR.P *n/(n-1)
Buongiorno Andrea,
Sono una principiante in statistica e fatico a capire come risolvere un esercizio così impostato: una certa ditta produce saponi il cui ph è 7.6. In un campione di 25 saponette scelte a caso da un rivenditore autorizzato il ph rilevato è pari a 8 e livello di significatività del 5%. Non ho deviazione standard e devo determinare associazione, test statistico, valore soglia e se rifiuto o accetto l’ipotesi nulla.
Da quello che ho capito studiando si tratta di un test a una coda in cui devo usare come test statistico il t student perché il campione è piccolo e non ho la deviazione standard Devo calcolare la varianza? Faccio la differenza tra le due medie diviso n – 1, estraggo la radice quadrata e quello diventa il mio s ?
Ciao Rosaria
No
I’m questo caso direi che si tratta di un test a due cose dove il valore centrale è quello ipotizzato 7,5
In secondo luogo il valore di t lo ricavi così:
t-test=(media c. – media h.)/SE
Dove:
Media c è la media del campione 8
Media h è la media ipotizzata
SE è l’errore standard associato al test
SE=radq(VAR C/n)
Dove
VARC è la varianza del campione
n è la numerosità del campione 25
Per calcolare la VAR C bisogna fare
VARC=somma(xi – mediac)^2 /(n-1)
Dove xi sono i dati del campione
Mediac è la media del campione
Ciao Andrea, l’esercizio in preparazione all’esame recita: le caratteristiche rilevate da un campione causale di 7 bambini ha fornito i seguenti valori del grado di reattività ad uno stimolo generico Y : 11, 9, 10, 10, 10, 11, 12 e 12. Assumendo che Y sia ben interpretato da una V.C. Normale:
a) calcolare la media campionaria del grado di reattività ad un stimolo generico Y
b) stimare la varianza del grado di reattività ad un stimolo generico Y e la varianza dello stimatore media campionaria Y
c) costruire un intervallo di confidenza per la media della variabile Y al livello del 95%
Grazie mille <3
Ciao Gaia
di questi punti quale sei riuscita a fare?
Ciao, scusate il disturbo ma non riesco a risolvere la lettera c del seguente esercizio:
Da una popolazione con u = 100 e varianza o? = 900
si estrae un campione di ampiezza n = 30.
a.Quanto valgono media e varianza della media campionaria?
b.Qual è la probabilità che X > 109?
c. Qual è la probabilità che 96 ≤ X ≤ 110?
d. Qual è la probabilità che X ≤ 107?
Qualcuno potrebbe, gentilmente, aiutarmi?
Ciao Mario.
Per prima cosa ricorda le proprietà della media campionaria.
La media delle medie è pari alla media.
Dunque la media delle stimatore MEDIA CAMP. campionaria è esattamente pari a u= 100
La varianza della MEDIA CAMPIONARIA è la varianza della popolazione divisa per la radice quadrata del numero di elementi del campione.
Dunque:
VAR (media C.) = 900 / radq(30) = 164,31
Immagino che quella che hai chiamato X sia la media campionaria.
Se così è proviamo a rispondere al quesito b.
Per prima cosa devi standardizzare quel 109.
Per standardizzarlo ti serve la deviazione standard delle medie campionario, che comunemente chiamo SE (standard error)
Lo standard error (SE) altro non è che la radice quadrata della varianza delle medie che abbiamo calcolato prima
dunque:
SE = radq(164,31) = 12,82
Adesso standardizziamo quel 109, chiamando z1 il suo valore standardizzato.
z1 = (109 – media) /SE = (109 – 100) / 12,82 = 0,70
Adesso la probabilità che X (media c.) sia maggiore di 109 è la stessa probabilità che z (sulla distribuzione normale standardizzata) risulti maggiore di 0,70.
Scritto matematicamente abbiamo che:
P(X>109) = P(z>0,70) =
Usando le tavole della normale standardizzata con ‘area sulla parte sinistra possiamo scrivere:
P(X>109) = P(z>0,70) = 1 – ∮(0,70) = 1-0,7580 = 0,242
Se hai avuto difficoltà a capire questa parte non avrai difficoltà a rispondere agli altri due quesiti.
In caso contrario ti invito a scoprire i due corsi che interessano questa parte.
PROBABILITA? e INFERENZA
https://andreailmatematico.it/corsi-statistica/
Che sono il secondo e il terzo corso di statistica
Nelle probabilità c’è la parte dedicata al funzionamento della distribuzione NORMALE
Nella parte dell’inferenza e i test di ipotesi ci sono sia gli intervalli di confidenza sulla media, che i test di ipotesi sulla media che è parte che ti riguarda in questa domanda
Ciao Andrea,
come si calcola una “media corretta per Abbott” (un ispettore me l’ha chiesta senza darmi altri elementi) ? ho come dati di partenza la media di 3 valori e la dev.st dei tre valori
Grazie
Ciao Marina
Sinceramente è la prima volta che sento questo nome
Forse intende dire un intervallo di confidenza ma non saprei
Magari cerca tra i materiali consigliati per la preparazione del test
Ho visto che alcune università o alcuni libri usano dei concetti molto singolari
E anche io scopro ogni volta dei nomi e indici nuovi
Ciao. Ho un esercizio banale su cui ho qualche dubbio, ovviamente nel testo (freedman- purves) non è spiegato nulla, lasciando all’estrema intelligenza dello studente la deduzione di ogni implicazione legata all sola introduzione della formula:
In un college il peso medio uomo è 66 Kg con SD 9 kg; peso medio donna 57 kg con SD 9 kg.
Se “prendo insieme” (scritto così nel testo, IPOTIZZO significhi fare la media dei pesi?) SD aumenta, diminuisce o rimane uguale? E perchè?
Trovo possibili tutte e 3 le cose: 1)aumenta: perchè aumenta la distanza max-min per cui la probabilità di avere valori più spalmati e il 68% si spalma.
2) rimane uguale, perchè disegnando sommariamente le curve in gran parte si sovrappongono, per cui SD rimane grosso modo uguale.
3) diminuisce, perchè spostandosi la media al centro dei 2 gruppi il 68% dei valori sarà più facilmente compreso, comprendendo in SD alcuni valori che prima erano fuori, concentrando il 68% in “meno spazio”.
Non ci ho capito niente… ma non ho il dono della divinazione come i matematici e non sono capace di dedurre ogni aspetto di un argomento dalla sola formula.
Grazie
Ciao Marcello
Questo esercizio si riferisce alla distribuzione normale oppure alla distribuzione delle medie campionarie ?
Da informazioni derivanti da una precedente analisi, si sa che la durata delle telefonate che arrivano a un call center si distribuisce in modo normale con media M incognita e varianza=16 minuti quadrati.
Si desidera calcolare la dimensione campionaria minima necessaria per costruire un intervallo della durata media delle chiamate a livello 95% che abbia ampiezza massima di 5 minuti.
Ciao Vittoria
Il primo dato importante di questo testo ci dice che conosciamo il valore della varianza della distribuzione il che ci porta alla tavola dei valori z della normale standardizzata.
Se invece il testo avesse parlato di varianza ignota della popolazione oppure ci avesse fornito direttamente il valore della varianza (o della deviazione standard) del campione ci saremmo proiettati sulle tavole della t-student.
Calcaliamo dunque dalle tavole della distribuzione normale standardizzata il valore di z associato al percentuale 0,95 che risulta pari a 1,645.
In secondo luogo teniamo bene a mente come si calcola il valori dell’intervallo I di confidenza
I = 2·z·𝛿/√n
dove z è il valore delle tavole, 𝛿 è la deviazione standard (radice di varianza), n la numerosità del campione.
Da questa formula dobbiamo ricavare il valore n
Moltiplicando per √n e dividendo per I otteniamo
√n = 2·z·𝛿/I
Eleviamo dunque al quadrato per ottenere n
n = (2·z·𝛿/I)² [ va bene anche scrivere n = 4·z²·𝛿²/I²]
Inseriamo dunque i dati a disposizione
n = (2·1,645·4/5)² =…
Da che hai la tua ampiezza
Ovviamente se trovi un numero con la virgola puoi tranquillamente approssimare per eccesso 😉
ciao Andrea, leggendo questo articolo mi è venuto un dubbio. se in un esercizio non è specificato se devo usare la varianza campionaria o della popolazione come faccio? perché in tutti gli esercizi mi danno una serie di dati (non dicendo se è un campione o una popolazione) e devo calcolare la varianza. come faccio a capire quale delle due formule usare? soprattutto perché noi con la popolazione non lavoriamo mai visto il numero immenso di dati
Ciao Franchetto,
Quando il numero di dati è immenso i risultati della norma le e quelli della t-student sono molto vicini
Diciamo che per campioni di 200/300 elementi le differenze sono impercettibili
Ad esempio il 95-esimo percentuale della z è 1,6448
i valori di t student sempre del 95-esimo percentuale sono:
1,6602 con 100 gradi di libertà
1,6525 con 200 gradi di libertà
1,6499 con 300 gradi di libertà
1,6479 con 500 gradi di libertà
Comunque sia se hai programmi elettronici usa la t-student che non sbagli
L’unica cosa è che se il testo dice ad esempio:
“dall’analisi dei dati storici (d quel fenomeno considerato) sappiamo che la varianza è…”
Allora in questo caso presupponi di conoscere il vero valore della varianza perciò puoi usare la z perché quei dati di varianza non si riferiscono al campione
Se però i dati sulla varianza (o deviazione standard) si riferiscono INEQUIVOCABILMENTE al campione analizzato allora qui la teoria generale dice di usare la t-student
Considera che una volta i calcoli si facevano a mano, e chi faceva faceva tali calcoli non sa niente sulle funzioni o della teoria sottostante
Chi ha fatto questa teoria dunque ha pensato di fornire dei valori sotto forma di tavole facendo questa semplificazione:
“Se il campione ha più di 30 o 60 o 100 unità allora al posto della t-studente usate la normale”
Queste soglie di 30, 60 o 100 dipendevano da quanto era accurata la costruzione delle tabelle
Per semplificare ulteriormente i calcoli a chi le usa i matematici hanno creato dei valori di riferimento per i test.
Se noti la maggior parte delle tavole per i calcoli a mano riporta solo alcuni valori critici significativi come ad esempio 0,5% 1%, 2%, 5%, 10%
Oggi in molte aziende dove si fanno dei test sul controllo della qualità i lavoratori più “anziani” vanno ancora “alla vecchia maniera” con le tavole.
Mentre per i più giovani si cerca (ma non sempre si riesce) ad indirizzarli sulla procedura più elettronica (che dovrebbe essere più accurata).
Ricorda che il vero obiettivo finale dei test è: PRENDERE UNA DECISIONE!
per fare questo ci sono supporti matematici.
Dunque i risultati che inserisci quando inserisce una t- student o una normale sono valori di una funzione esponenziale.
La normale è il punto di riferimento UNIVERSALE di tutta la statistica: è un po’ come DIO cioè perfetto, immutabile, non ha difetti.
Poi attorno a quella funzione si sono costruite delle varianti come ad esempio la t-student che tengono conto di altre variabili sulla base ad esempio del numero di elementi del campione.
Queste varianti tengono conto di una maggior numero di informazioni quando i dati sono riferiti al solo campione dunque forniscono dei risultati “più precisi”.
Quindi la matematica offre agli statistici queste funzioni.
Gli statistici a loro volta offrono a chi deve prendere le decisioni dei modelli pratici
Poi chi prende le decisioni fa una specie di “gioco d’azzardo” (che si basa proprio sulle percentuali del test) per prendere la decisione.
Una volta che la decisione è presa l’effetto può essere duplice: vinco oppure perdo.
Se vinco continuo a tenere buono il modello.
Se perdo cambio le percentuali, ricontrollo i dati, integro dei dati, valuto se servono altri test.
Poi il gioco ricomincia 😉
Ciao Andrea,
Volevo chiederti: perché dividendo per n la varianza campionaria risulta distorta? E perché la soluzione sta nella sottrazione da n solo 1?
Ciao Davide, ottima domanda 😉
Ho completato all’articolo con altre due sezioni:
– Perché la Varianza Campionaria è “Timida”?
– In sintesi: Perché proprio $n-1$?
– La Guida Definitiva ai Correttori della Varianza
Nella prima ho fatto un esempio pratico molto semplice,
Mentre nella seconda vi è la dimostrazione generale (matematica) dell’affermazione
Spero che il contenuto possa aiutarti a sciogliere ogni dubbio.
Nella terza ho riassunto dal punto di vista teorico tutte le possibilità in cui i campioni possono essere estratti, evidenziando la relazione tra varianza campionaria non corretta, numerosità del campione (n) e numerosità della popolazione (N)
Un caro saluto